一、HDFS shell命令;二、使用Shell命令执行Hadoop自带的WordCount;三、安全模式;四、HDFS Web界面
一、HDFS shell命令
调用文件系统(FS)的Shell命令具有下面的形式
1 | hadoop fs -cmd <args:uri> |
所有的FS shell命令使用URI路径作为参数。URI格式是
1 | scheme://authority/path |
注:统一资源标识符(Uniform Resource Identifier,URI)是一个用于标识某一互联网资源名称的字符串。 该种标识允许用户对任何(包括本地和互联网)的资源通过特定的协议进行交互操作。
对HDFS文件系统,scheme是hdfs**。对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。一个HDFS文件或目录比如*/parent/child*可以表示成
1 | hdfs://namenode:namenodeport/parent/child |
如果配置文件中设置了默认值namenode:namenodeport,比如我们在安装Hadoop时,在core-site.xml文件中设置的localhost:9000,

URI可以简写为
1 | /parent/child |
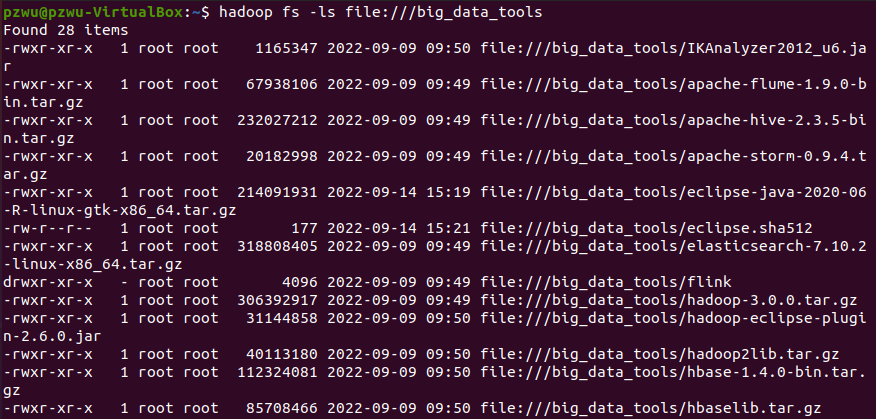
大多数FS Shell命令的行为和对应的Linux Shell命令类似。例如,查看本地目录
/home/lei/big_data_tools中内容
1 | hadoop fs -ls file:///big_data_tools |
接下来我们练习常用的命令。为了演示后面的命令,在本地/data目录下新建两个文件,/data/testfile1和/data/testfile2,内容分别为Hello big data!和Hello hadoop!

mkdir
在HDFS文件系统创建新目录,只能创建一级目录。创建多级目录上一级目录必须存在,或使用-p参数。
使用方法:hadoop fs -mkdir
例如,在HDFS根目录下的input目录下创建files目录。如果/input目录不存在,需要加-p参数。
1 | hadoop fs -mkdir -p /input/files |

put
上传本地文件系统中单个或多个文件到HDFS文件系统。
使用方法:hadoop fs -put local:Files hdfs:Directory
例如,上传/data/testfile1和/data/testfile2到新创建的目录/input/files中,可以两个文件分别上传,
1 | hadoop fs -put /data/testfile1 /input/files |

也可以使用一条命令,同时上传两个文件
1 | hadoop fs -put /data/testfile1 /data/testfile2 /input/files |
ls
查看文件或目录,如果是文件,返回文件的信息,如果是目录,返回它直接子目录的文件列表。加上-R选项以递归方式查看目录下所有文件
使用方法:hadoop fs -ls hdfs:Directory
例如,查看/input/files目录,确认我们的两个文件是否上传成功。
1 | hadoop fs -ls /input/files |

查看文件/input/files/testfile1的信息
1 | hadoop fs -ls /input/files/testfile1 |

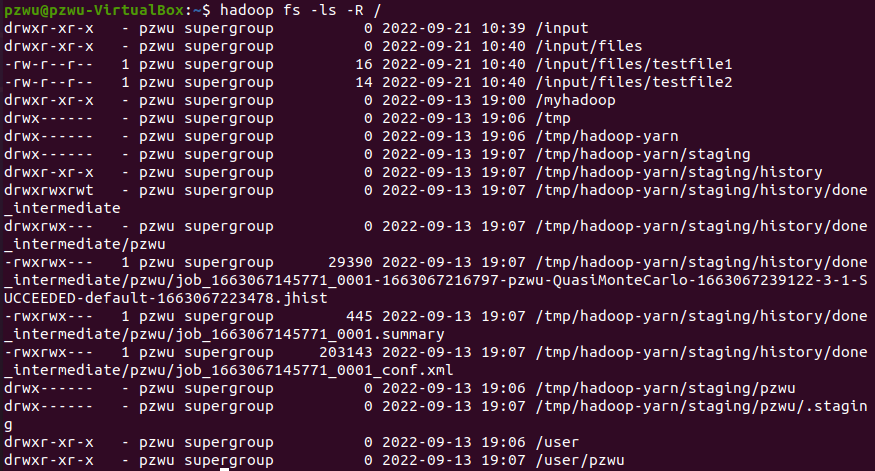
查看根目录下所有文件
1 | hadoop fs -ls -R / |
cat
查看指定文件的内容
使用方法:hadoop fs -cat URI [URI …]
例如,查看/input/files/testfile1的内容
1 | hadoop fs -cat /input/files/testfile1 |

查看一个目录下所有文件的内容可以使用通配符*
例如,查看目录/input/files/的所有文件的内容,命令为
1 | hadoop fs -cat /input/files/* |

rm
删除指定的文件,加上-r 选项可以删除指定目录。
使用方法:hadoop fs -rm hdfs:File
例如,删除文件/myhadoop/testfile1(如果不存在,先创建)
1 | hadoop fs -rm /myhadoop/testfile1 |

例如,删除目录/myhadoop
1 | hadoop fs -rm -r /myhadoop/ |

cp
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
使用方法:hadoop fs -cp hdfs:File hdfs:Directory
例如,复制/input/files/目录中的两个文件到HDFS根目录下
1 | hadoop fs -cp /input/files/testfile1 /input/files/testfile2 / |

get
从HDFS文件系统下载文件到本地目录,***本地目录必须存在***。
使用方法:hadoop fs -get hdfs:File local:Directory
例如,下载/input/files/testfile1文件到当前用户家目录下
1 | hadoop fs -get /input/files/testfile1 ~/ |


mv
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录,也可在移动的同时对文件进行改名。
使用方法:hadoop fs -mv hdfs:source hdfs:target
例如:将文件/testfile1 移动到目录/input
1 | hadoop fs -mv /testfile1 /input/ |

例如:将文件/testfile2 移动到目录/input/files,并改名为testfile3。
1 | hadoop fs -mv /testfile2 /input/files/testfile3 |

test
检查一个文件或目录是否存在,存在返回0,否则返回1。
使用方法:hadoop fs -test –[ed] hdfs:target
选项:
-e 检查文件是否存在
-d 检查目录是否存在
例如:检查/input/files/testfile1是否存在
1 | hadoop fs -test -e /input/files/testfile1 |

检查目录/input是否存在
1 | hadoop fs -test -d /input/ |

命令的返回值没有直接显示在终端中,需要使用echo命令查看。返回0,说明存在,返回1,说明不存在。
1 | echo $? |
注:echo $? 上个命令的退出状态,或函数的返回值
二、使用Shell命令执行Hadoop自带的WordCount
本小结我们练习将HDFS上的数据文件作为输入,运行Hadoop自带的词频统计程序。将HDFS上/inputs/files/目录中三个的文件作为输入,

三个文件的内容为

词频统计结果将输出到目录/output/wordcount,注意/output/wordcount不能提前存在。
执行hadoop jar命令,在hadoop的/apps/hadoop/share/hadoop/mapreduce路径下存在hadoop-mapreduce-examples-3.0.0.jar包,执行其中的worldcount类,输入为HDFS的/input/files目录下的文件,结果输出到HDFS的/output/wordcount目录。
1 | hadoop jar /apps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /input/files /output/wordcount |

查看HDFS中的/output/wordcount目录
1 | hadoop fs -ls /output/wordcount/ |

查看结果,结果保存在part-r-00000中。
1 | hadoop fs -cat /output/wordcount/part-r-00000 |

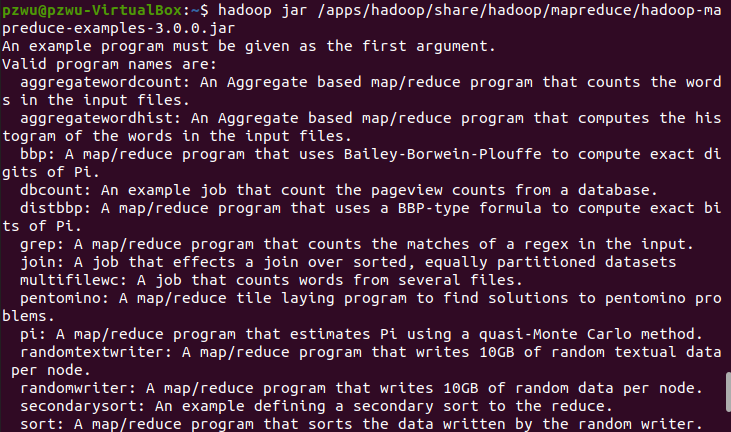
查看hadoop自带的还有哪些例子
1 | hadoop jar /apps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar |
三、安全模式
在分布式文件系统启动的时候,会进入安全模式,分布式文件系统处于安全模式下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期间通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
进入Hadoop安全模式
1 | hdfs dfsadmin -safemode enter |
退出Hadoop安全模式
1 | hdfs dfsadmin -safemode leave |

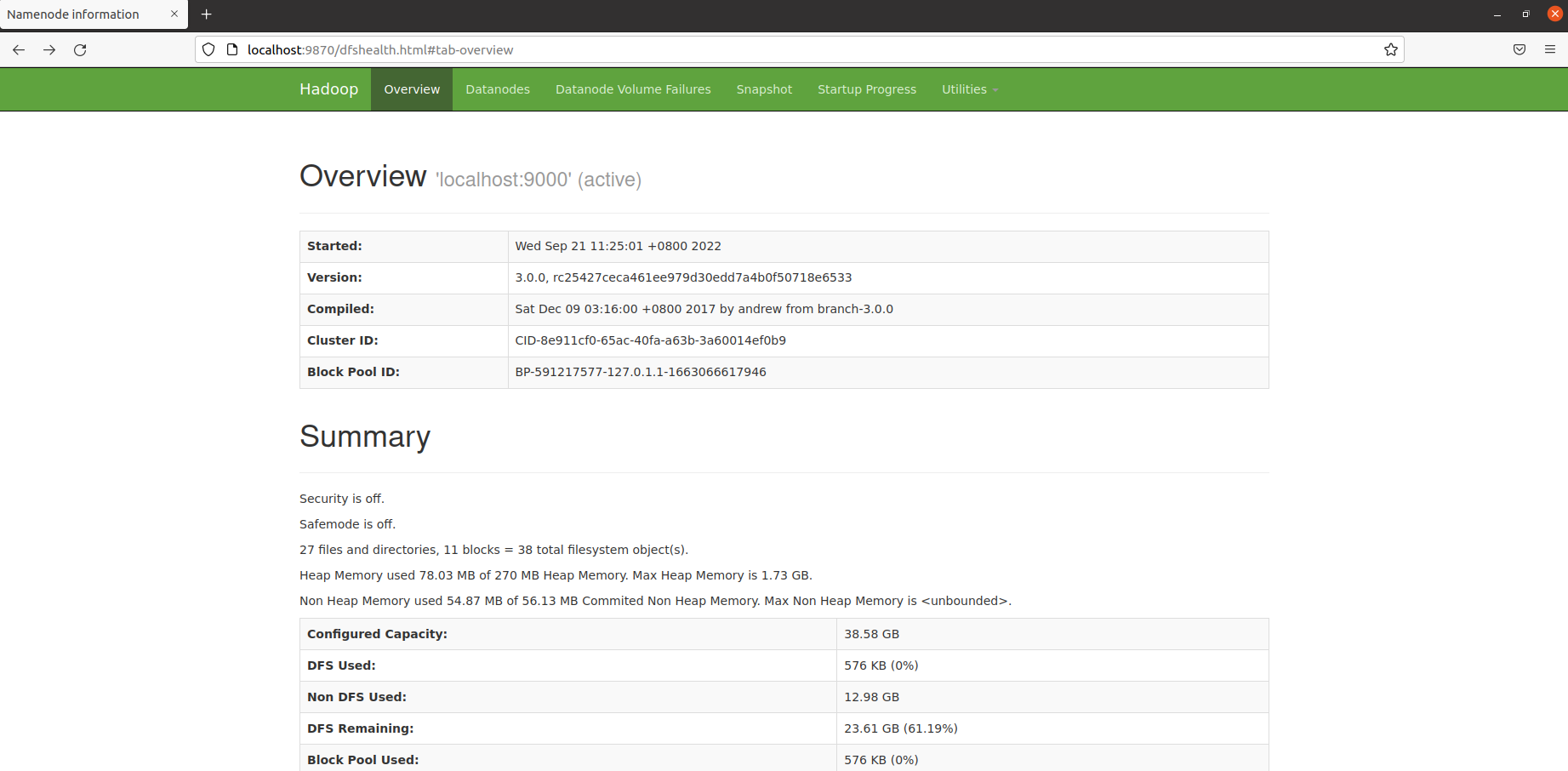
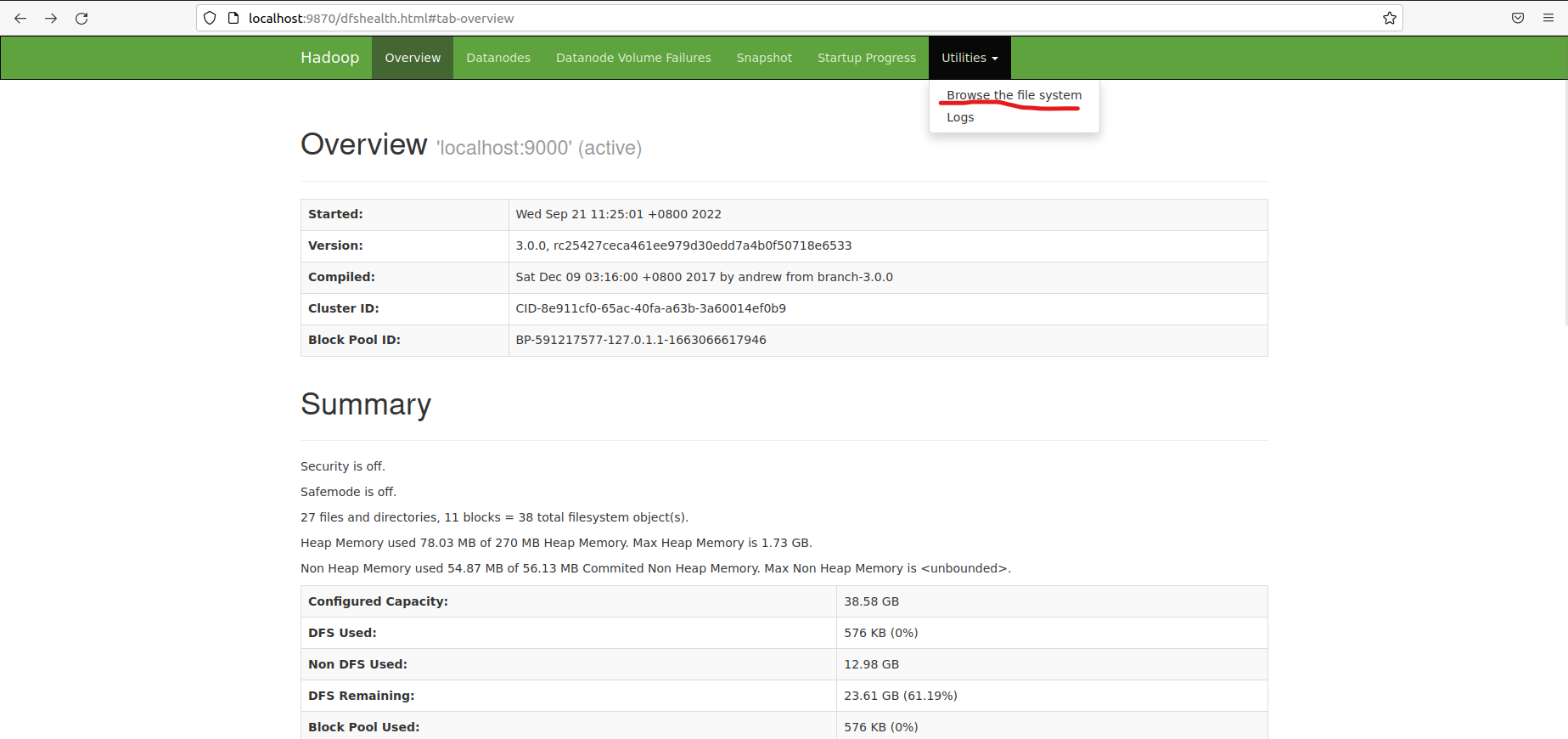
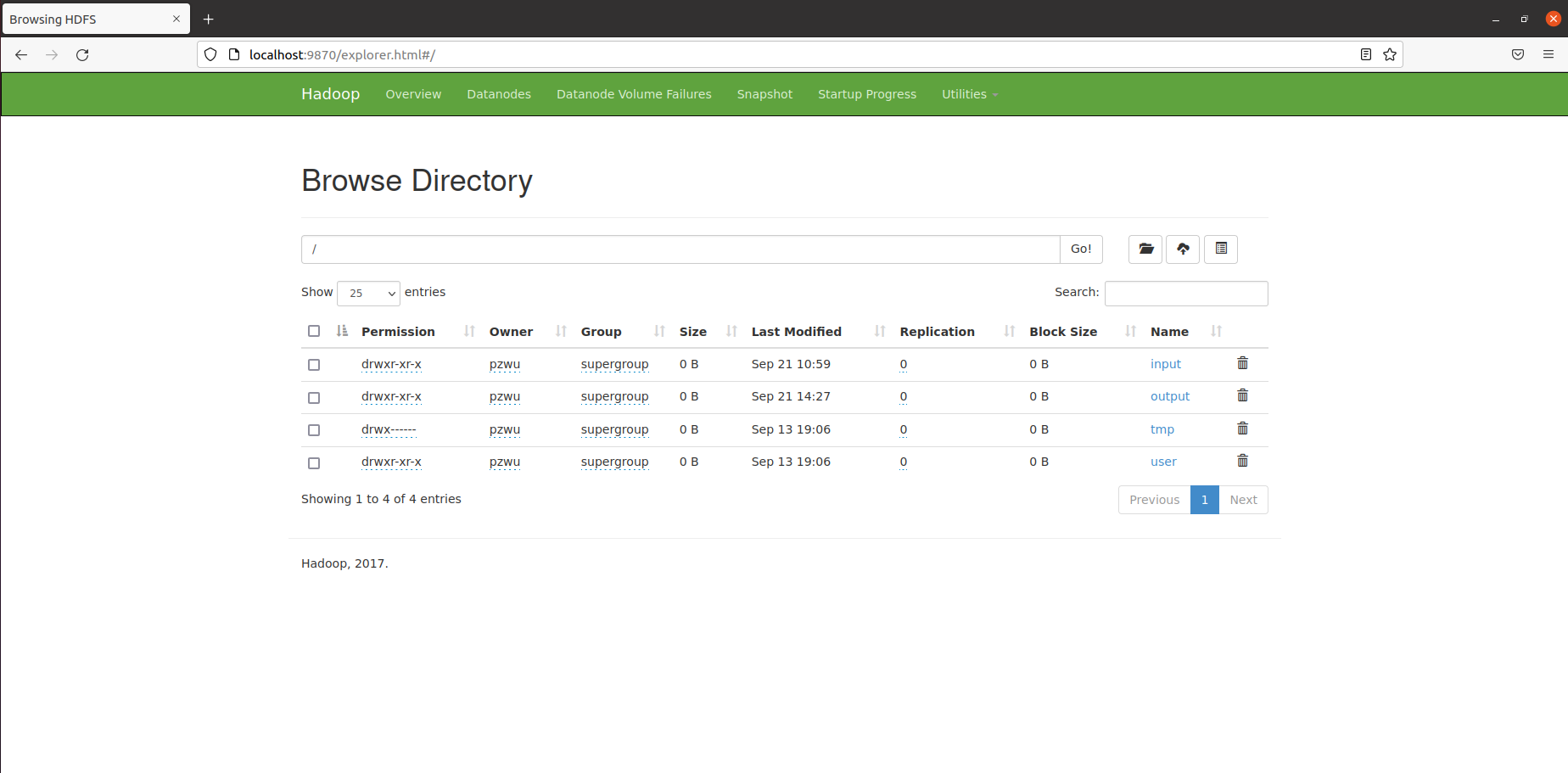
四、HDFS Web界面
在浏览器中访问http://localhost:9870,可以查看HDFS相关信息,浏览HDFS上的文件系统。