一、Hadoop Streaming介绍;二、中文分词;三、任务失败日志查看方法;四、遇到的问题
Hadoop框架是用Java语言写的,也就是说,Hadoop框架中运行的所有应用程序都要用Java语言来写才能正常地在Hadoop集群中运行。如果不会Java语言怎么办?Hadoop提供了Hadoop Streaming这个编程工具,它允许用户使用任何可执行文件或者脚本文件作为Mapper和Reducer,因此我们可以选择自己熟悉的编程语言,编写Mapper和Reducer程序来使用Hadoop集群。
一、Hadoop Streaming介绍
Streaming的原理是用Java实现一个包装用户程序的MapReduce程序,该程序负责调用MapReduce Java接口获取key/value对输入,创建一个新的进程启动包装的用户程序,将数据通过管道传递给包装的用户程序处理,然后调用MapReduce Java接口将用户程序的输出切分成key/value对输出。
我们以Python语言为例,Mapper文件内容如下
1 | import sys |
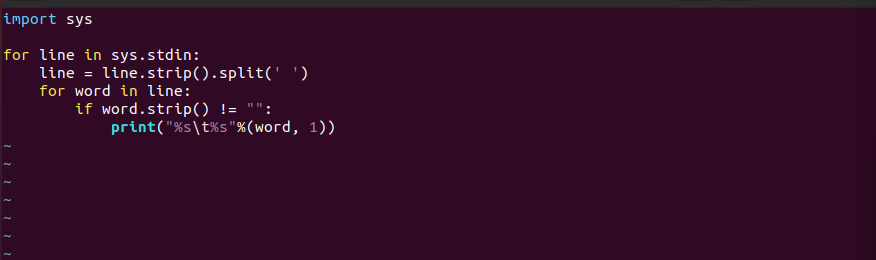
Reducer文件内容如下
1 | import sys |
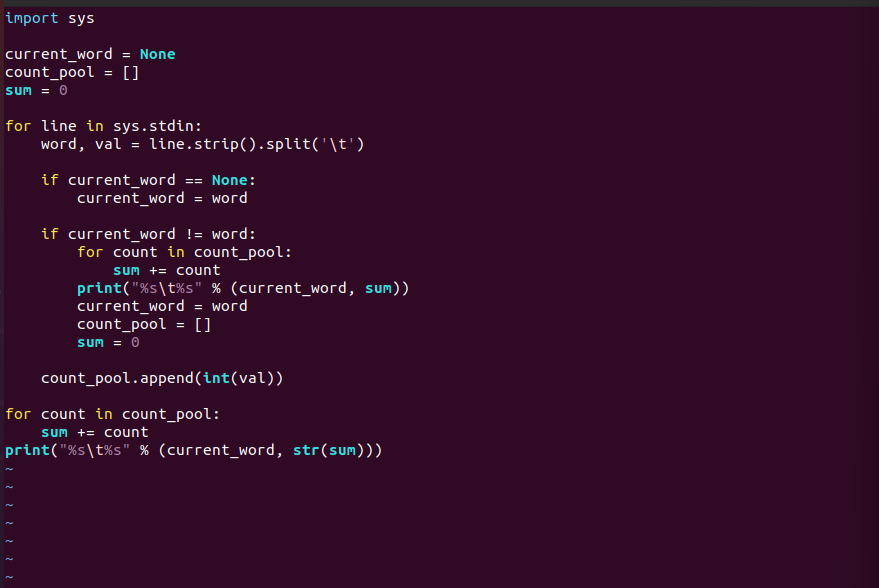 将上面的代码分别保存成mapper.py和reducer.py,使用shell命令的管道功能测试Mapper和Reducer程序。命令如下:
将上面的代码分别保存成mapper.py和reducer.py,使用shell命令的管道功能测试Mapper和Reducer程序。命令如下:
1 | cat testfile | python3 mapper.py | sort -t $'\t' -k 1 | python3 reducer.py |

将testfile作为数据传递给mapper.py处理,再将处理结果进行排序,之后再把排序结果交给reducer.py处理,testfile可以用前面测试WordCount的文件。需要注意:
这里我们可以使用python3 +文件名来运行python程序,也可以在python程序首行指明解释程序然后赋予可执行权限。例如在mapper.py首行添加
1 | \#!/usr/bin/python3 |
然后添加可执行权限
1 | chmod u+x mapper.py |
可以通过指明mapper.py文件的路径来执行,比如在当前目录下执行
1 | ./mapper.py |
sort为排序命令,-t表示指定分隔符,-t $’\t’表示用tab进行分隔,-k表示排序时指定的键是在分隔后的哪个field,-k 1表示按分隔符分隔后的第一个field,也即我们在mapper中打印的key/value中的key。
如果管道测试能够输出我们期望的结果,就可以将任务放到Hadoop集群上运行。命令格式如下
1 | Usage: $HADOOP_HOME/bin/hadoop jar hadoop-streaming.jar [options] |
常用的参数有
-input
:指定作业输入,path可以是文件或者目录,可以使用*通配符,-input选项可以使用多次指定多个文件或目录作为输入。 -output
:指定作业输出目录,path必须不存在,而且执行作业的用户必须有创建该目录的权限,-output只能使用一次。 -mapper:指定mapper可执行程序或Java类,必须指定且唯一。
-reducer:指定reducer可执行程序或Java类,必须指定且唯一。
-file, -cacheFile, -cacheArchive:分别用于向计算节点分发本地文件、HDFS文件和HDFS压缩文件。
-numReduceTasks:指定reducer的个数,如果设置-numReduceTasks 0或者-reducer NONE则没有reducer程序,mapper的输出直接作为整个作业的输出。
-jobconf / -D NAME=VALUE:指定作业参数,NAME是参数名,VALUE是参数值,可以指定的参数可以参考hadoop-default.xml。
也可以通过以下命令查看完整的命令参数介绍
hadoop jar /apps/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.0.0.jar --help
我们可以将上述命令写成一个shell脚本方便使用。首先将hadoop-streaming-3.0.0.jar的路径和程序输入输出路径保存成变量。其次,我们判断输出目录是否已经存在,如果存在就删除。最后是hadoop streaming 命令,在命令中我们给任务起名为“WordCount”。
1 | STREAMING_JAR_PATH=/apps/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.0.0.jar |
从上面的过程可以看出,Mapper和Reducer都是可执行文件,它们从标准输入读入数据(一行一行读), 并把计算结果发给标准输出。Streaming工具会创建一个Map/Reduce作业, 并把它发送给合适的集群,同时监视这个作业的整个执行过程。如果一个可执行文件被用于Mapper,则在Mapper初始化时, 每一个Mapper任务会把这个可执行文件作为一个单独的进程启动。 Mapper任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,Mapper收集可执行文件进程标准输出的内容,并把收到的每一行内容转化成key/value对,作为Mapper的输出。 默认情况下,一行中第一个Tab之前的部分作为Key,之后的(不包括Tab)作为Value。 如果没有Tab,整行作为Key值,Value值为null。不过,这可以定制。如果一个可执行文件被用于Reducer,每个Reducer任务会把这个可执行文件作为一个单独的进程启动。 Reducer任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,Reducer收集可执行文件进程标准输出的内容,并把每一行内容转化成Key/Value对,作为Reducer的输出。 默认情况下,一行中第一个Tab之前的部分作为Key,之后的(不包括Tab)作为Value。
二、中文分词
使用Hadoop streaming对文本文件vehicle.txt进行中文分词,并统计词频。分词可以选用jieba分词工具。
1、准备jieba分词包
更新可用软件包列表
1 | sudo apt update |

安装pip3
1 | sudo apt install python3-pip |

安装jieba分词
1 | pip3 install jieba |
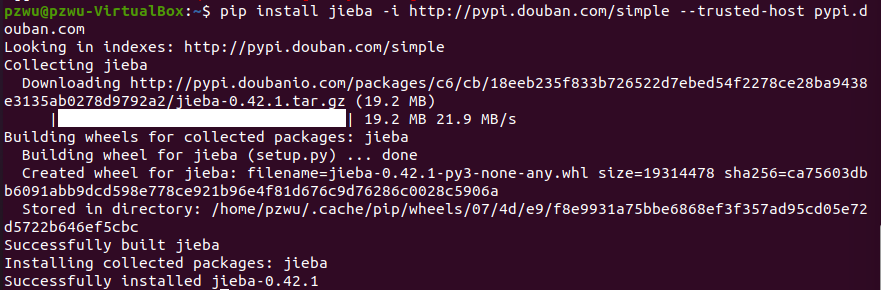
进入Python3交互模式
1 | python3 |
导入jieba,并查看jieba安装目录
1 | import jieba |
1 | jieba.__file__ |

可以看到jieba所在目录为/home/pzwu/.local/lib/python3.8/site-packages/jieba
退出Python3交互模式
1 | exit() |
复制jieba整个文件夹到~/big_data_tools
1 | cp -r /home/lei/.local/lib/python3.6/site-packages/jieba ~/big_data_tools/ |

打包
1 | cd ~/big_data_tools |
1 | tar zcvf jieba.tar.gz jieba |


上传到hdfs
1 | hadoop fs -mkdir /py_modules |
1 | hadoop fs -put jieba.tar.gz /py_modules |

检查一下是否上传成功
1 | hadoop fs -ls /py_modules |

进入~/hadoop_streaming/wordcount
1 | cd ~/hadoop_streaming/wordcount |

创建 map 文件
新建mapper.py,写入如下内容
1 | #!/usr/bin/python3 |
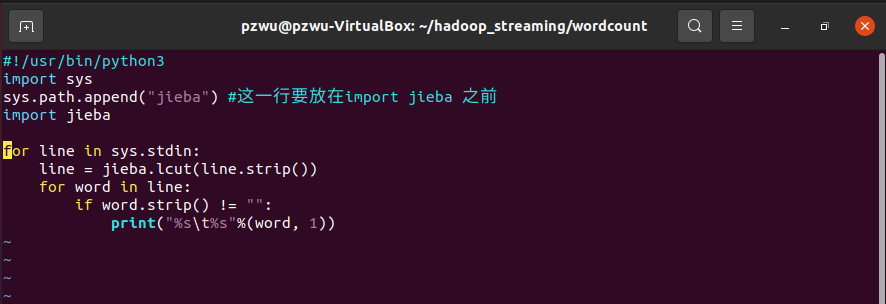
- 创建recuder文件
新建reducer.py,写入如下内容
1 | #!/usr/bin/python3 |
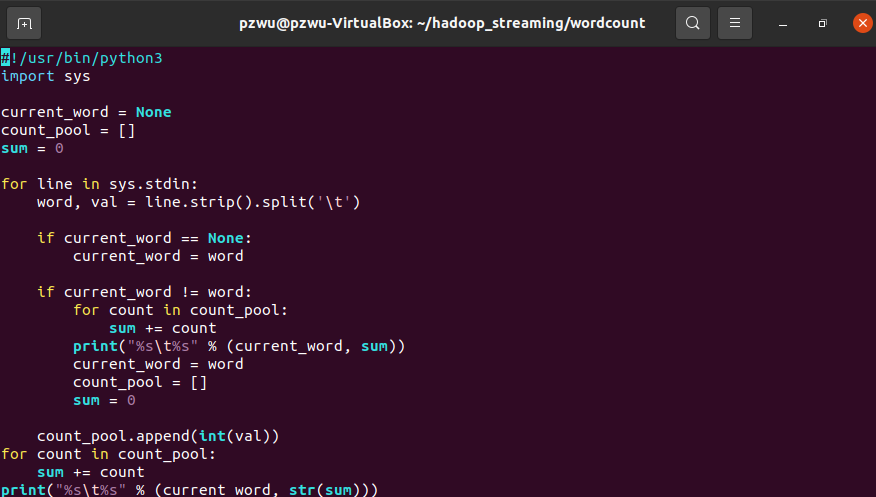
- 创建执行脚本文件
新建脚本文件run.sh,写入如下内容
1 | #!/bin/bash |
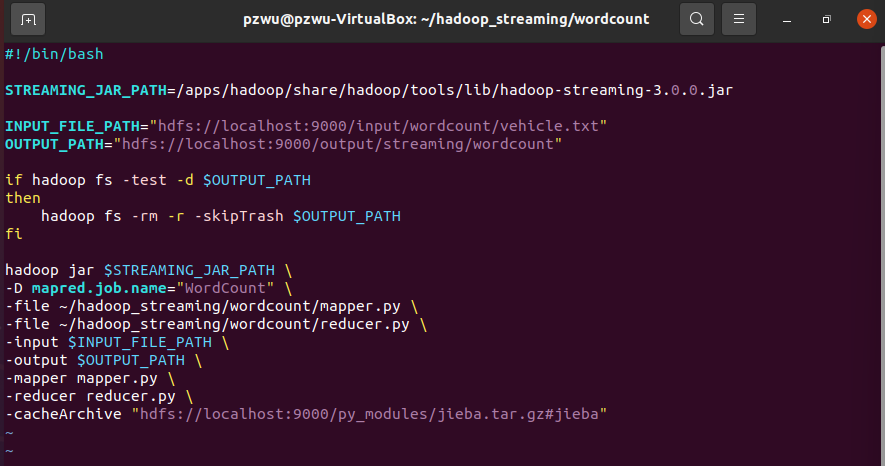
注意输入文件的路径为hdfs://localhost:9000/input/wordcount/vehicle.txt,需要提前把vehicle.txt文件上传到HDFS。另外,为了区分本地路径和HDFS的路径,这里统一在HDFS的路径前加了地址hdfs://localhost:9000。
vehicle.txt文件上传到HDFS

- 运行脚本
1 | bash run.sh |


出现以上信息显示成功完成并显示输出路径,说明job运行成功。就可以去HDFS查看结果了。
- 查看结果
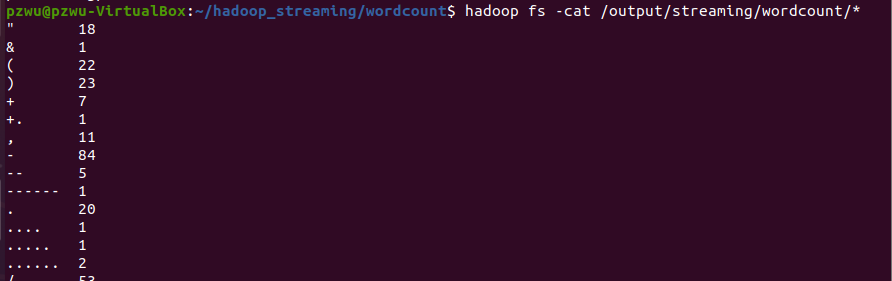
使用下面的命令打印输出文件内容
1 | hadoop fs -cat /output/streaming/wordcount/* |
三、任务失败日志查看方法
在终端中,通过运行过程中的产生的日志信息可以获得任务ID。
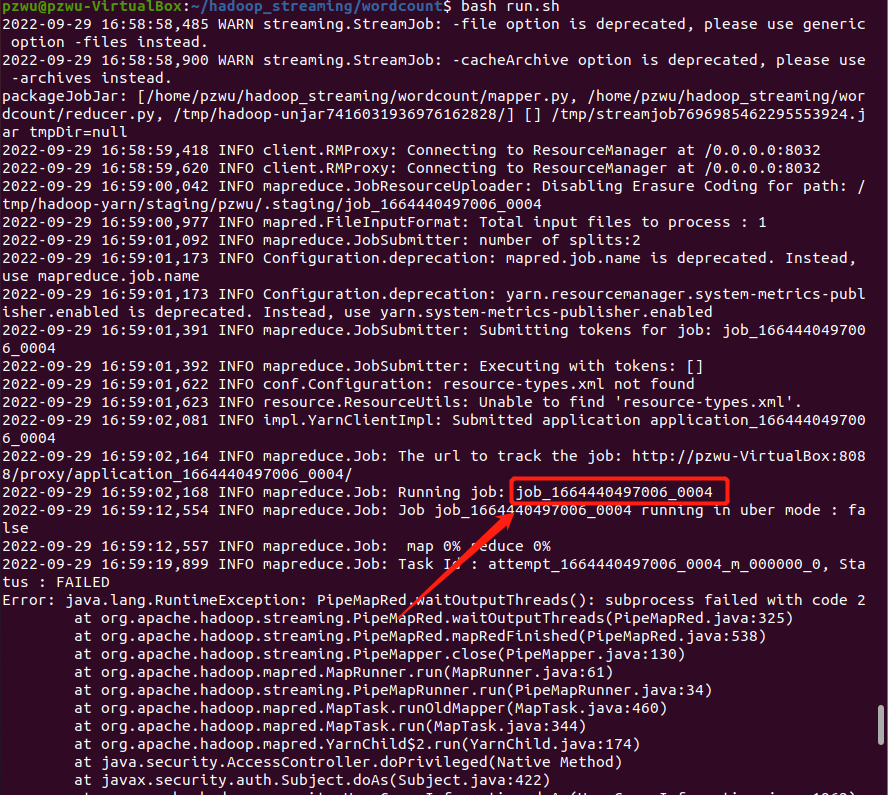
日志信息存在/apps/hadoop/logs/userlogs/以job ID命名的目录中。

如果我们的任务运行失败,可以分别进入各个目录,查看其中的stderr文件,错误信息会显示在其中。

以streaming中文分词实验为例,我们将mapper.py中的导入jieba语句模块注释掉。
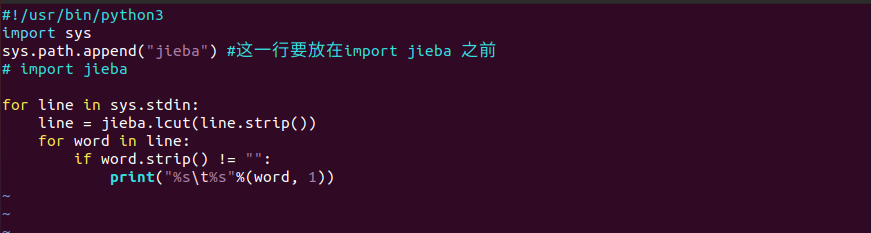
再次执行任务脚本,在终端中我们只能看到如下任务失败的日志,并不能获得详细信息。
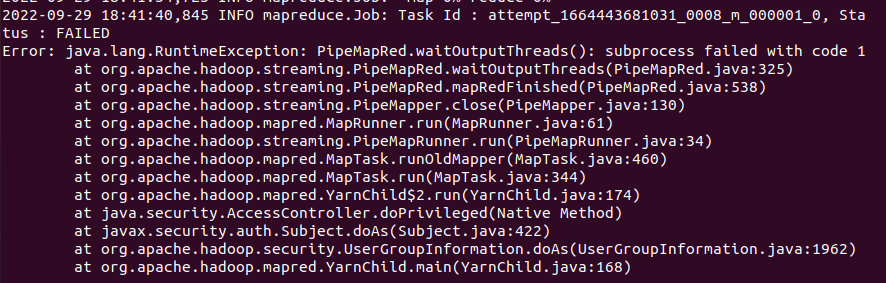

查看我们container日志文件,可以得到下图中信息错误原因,就是我们没有导入jieba模块造成的python不认识jieba这个名字
修改后再次执行即可。
四、遇到的问题
1、下载jieba报错
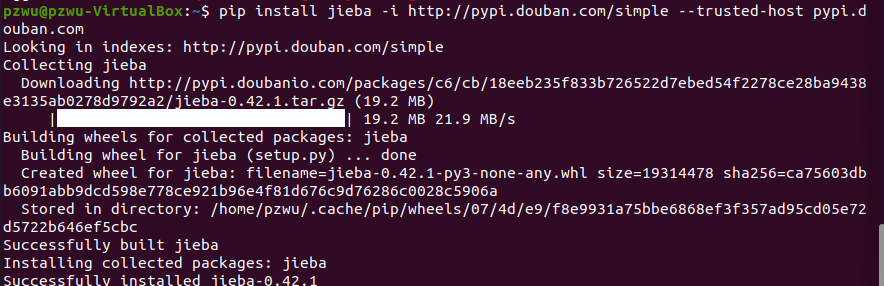
遇到报错如下,连接超时,可能是原本的源速度太慢
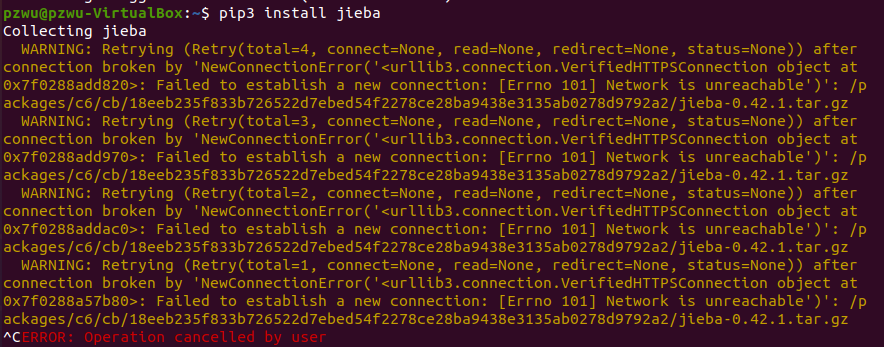
更换豆瓣源,

查看报错host不被信任,加上后缀–trusted-host
1 | pip install [whatyouwant] -i http://pypi.douban.com/simple --trusted-host pypi.douban.com |
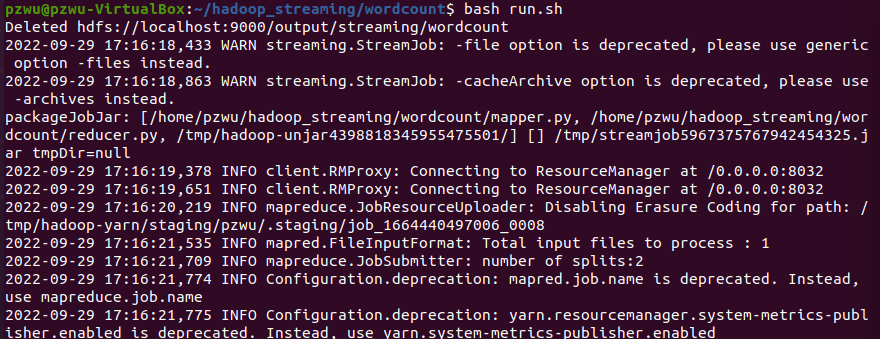
2、报错显示内存不足
报错如下,内存不足
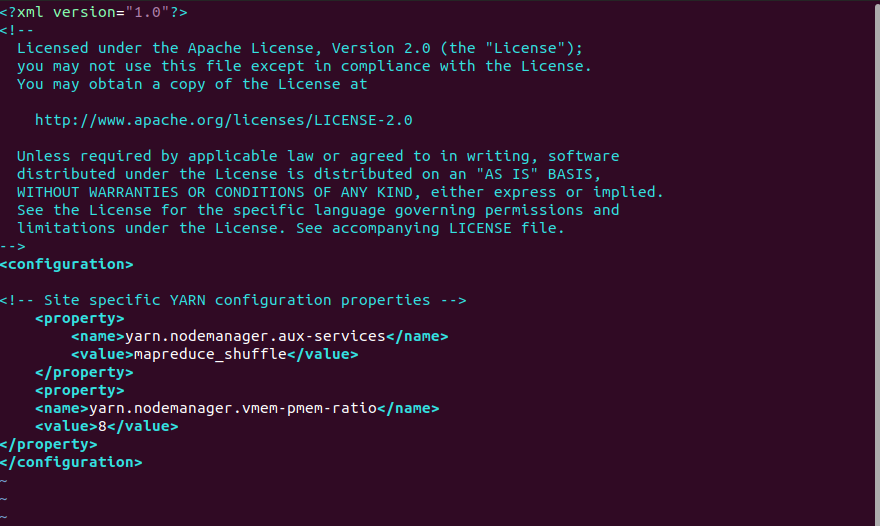
解决方案:在/apps/hadoop/etc/hadoop/下的yarn-site.xml添加如下配置,提高虚拟内存比例

1 | <property> |
内存不足未尝试解决方案
方案一:
在mapred-site.xml 中添加如下配置
1 | <property> |
方案二
在yarn-site.xml中添加如下配置
1 | <property> |
- 设置是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
- 设置是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
内存报错分析
物理内存:内存条提供的内存
虚拟内存:利用磁盘空间虚拟划出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。为了满足物理内存的不足而提出的策略。
Linux系统会在物理内存不足时,使用交换分区的虚拟内存。内核会将暂时不用的内存块信息写到交换空间,这样以来,物理内存得到了释放,这块内存就可以用于其它目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
MapReduce****配置参数:
(1)mapreduce.map.memory.mb
默认值:1024(MB),表示每个MapReduce作业的map任务可以申请的内存资源数量。
(2)mapreduce.reduce.memory.mb
默认值:1024(MB),表示每个MapReduce作业的reduce任务可以申请的内存资源数量。
Yarn 的配置参数:
(1)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(2)yarn.nodemanager.vmem-pmem-ratio
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。
(3) yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(4) yarn.nodemanager.vmem-check-enabled
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(5)yarn.scheduler.minimum-allocation-mb
单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
(6)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最大物理内存量,默认是8192(MB)。
默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。
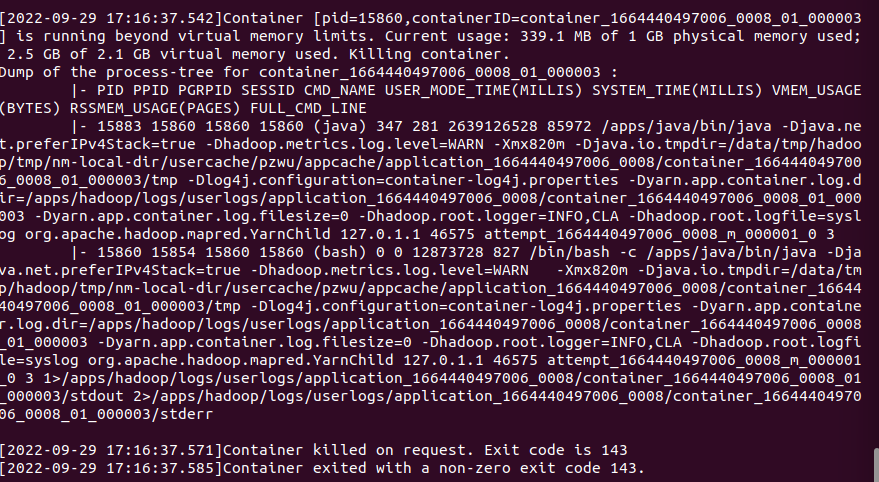
如果日志中出现以下错误:

各个数值的含义:
- 1G为yarn.scheduler.minimum-allocation-mb的值或者它的整数倍,当yarn.scheduler.minimum-allocation-mb大于mapreduce.map.memory.mb的值则默认分配yarn.scheduler.minimum-allocation-mb,小于则取yarn.scheduler.minimum-allocation-mb的整数倍,最大不超过yarn.scheduler.maximum-allocation-mb 内存值,
- 114.6MB为mr任务map Container实际占用的物理内存,
- 2.1G为map Container默认分配的内存值乘以 yarn.nodemanager.vmem-pmem-ratio(默认2.1),
- 2.4G为map Container任务实际占用的虚拟内存。