一、准备工作
1.安装vim
sudo apt install vim
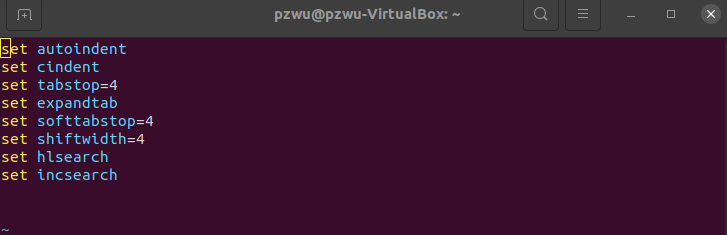
配置vim
打开~/.vimrc,添加以下内容
set autoindent
set cindent
set tabstop=4
set expandtab
set softtabstop=4
set shiftwidth=4
set hlsearch
set incsearch
2.安装SSH服务端
由于集群中主机进行分布式计算需要相互进行数据通信,服务器之间的连接需要通过SSH进行,所以需要安装SSH服务。
SSH(Secure Shell)是一套远程传输通信协议,用于实现两台机器之间的安全登录以及数据传送,其保证数据安全的原理是非对称加密。
Ubuntu缺省已经安装了SSH 客户端,这里只需安装服务端
sudo apt install openssh-server
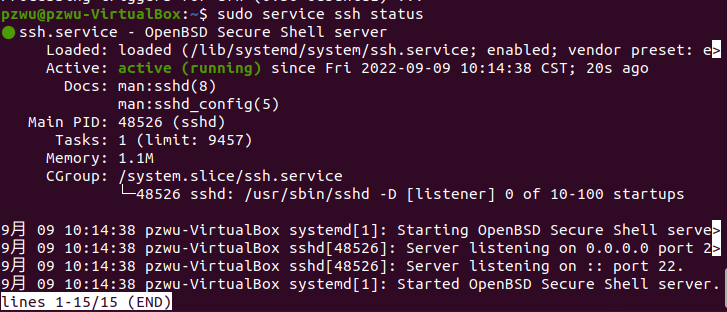
安装以后,SSH服务端会自动开启,执行以下命令查看服务状态
sudo service ssh status
如果服务没有开启,可以执行下面的命令开启服务
sudo service ssh start
3.配置SSH免密码登录
默认通过SSH登录服务器需要输入用户名和密码,如果Hadoop每次都通过输入密码访问节点将非常麻烦,所以需要设置使用公钥登录。所谓“公钥登录“,就是用户将自己的公钥储存在远程主机上。登录的时候,远程主机会向用户发送一段随机字符串,用户用自己的私钥加密后,再发回来。远程主机用事先储存的公钥进行解密,如果成功,就证明用户是可信的,直接允许登录shell,不再要求密码。
执行以下命令,生成公钥和私钥对,-t选项用于指定加密算法类型,比如RSA、ECDSA或DSA等。
ssh-keygen -t rsa
此时会有多处提醒在冒号后输入文本,主要是要求输入SSH密码以及密码的放置位置。只需要使用默认值,按回车即可。
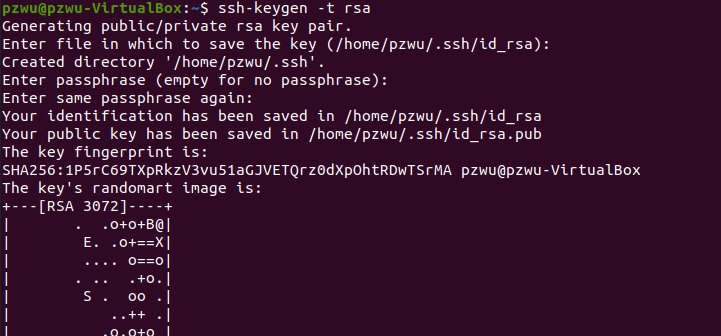
此时SSH公钥和私钥已经生成完毕,且放置在/.ssh目录下。切换到/.ssh目录下可以看到有两个文件:id_rsa和id_rsa.pub,分别存储私钥和公钥。

在~/.ssh目录下,创建一个名为authorized_keys的文本文件
touch ~/.ssh/authorized_keys
将公钥文件id_rsa.pub里的内容,追加到authorized_keys中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

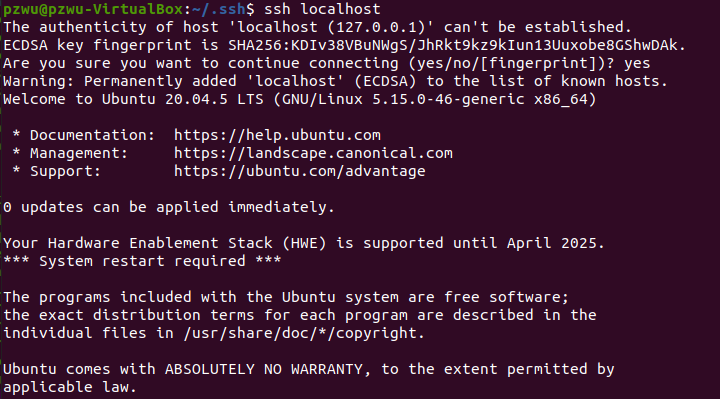
执行ssh localhost测试公钥登录配置是否正确
ssh localhost
第一次使用ssh访问,会提醒是否继续连接,输入“yes”继续进行,如果没有提示输入密码,则证明免密码登录成功,执行完以后执行exit退出。

后续再执行ssh localhost时,就不用输入密码了。
4.账号设置
为了后面操作方便,将自己的Linux系统账号提升为管理员(系统安装时设置的账号默认具有管理员权限,无需操作),例如,下面将账号lei设置为管理员。
sudo usermod -aG sudo pzwu

二、Hadoop伪分布式安装
1.新建安装目录
首先来创建两个目录,用于存放安装程序及数据。两个目录的作用分别为:
/apps目录用来存放安装的框架
/data目录用来存放临时数据、HDFS数据、程序代码或脚本。
sudo mkdir /appssudo mkdir /data

并将两个目录的所有者及所属组从root改为我们自己的账户pzwu
sudo chown -R lei:lei /apps
sudo chown -R lei:lei /data

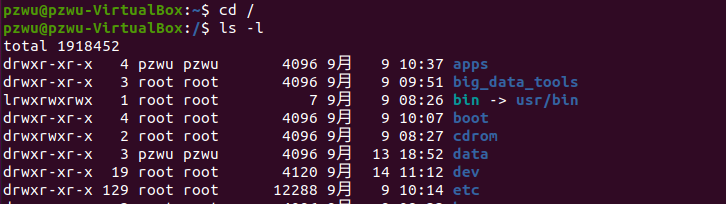
切换到根目录下,执行 ls -l 命令验证是否创建成功
ls -l
可以看到根目录下/apps和/data目录所有者及所属组已切换为pzwu:pzwu
2.复制安装包
复制需要的安装包到/apps目录下,如jdk(Java Development Kit )安装包jdk-8u191-linux-x64.tar.gz及Hadoop安装包hadoop-3.0.0.tar.gz。假设安装包已经下载到家目录的big_data_tools(需要自己创建)目录下
cp ~/big_data_tools/hadoop-3.0.0.tar.gz /apps/
cp ~/big_data_tools/jdk-8u191-linux-x64.tar.gz /apps/
3.安装jdk
进入目录/apps,并解压jdk-8u191-linux-x64.tar.gz。
cd /apps
tar zxvf jdk-8u191-linux-x64.tar.gz
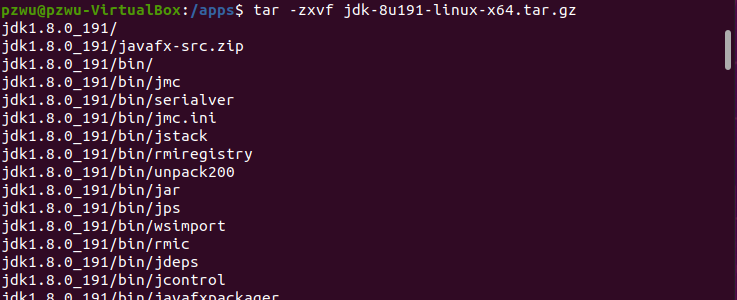
确认一下解压是否有报错,如果有报错信息,需要检查一下压缩文件的完整性。将jdk1.8.0_191目录重命名为java
mv /apps/jdk1.8.0_191/ /apps/java
删除压缩包
rm /apps/jdk-8u191-linux-x64.tar.gz
用vim打开用户个性化配置文件
vim ~/.bashrc
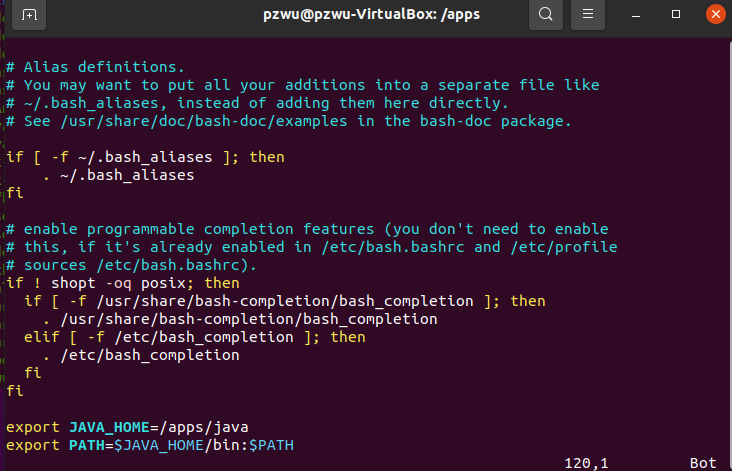
配置环境变量,在文件末尾添加Java环境变量,保存退出。
1 | # Java |
执行source命令让环境变量生效。
source ~/.bashrc

测试环境变量,
java -version
出现如下,显示Java的版本号,则说明安装正确。

4.安装Hadoop
进入目录/apps,解压hadoop-3.0.0.tar.gz
cd /apps
tar zxvf hadoop-3.0.0.tar.gz

将hadoop-3.0.0重命名为hadoop。
mv /apps/hadoop-3.0.0/ /apps/hadoop

将Hadoop的路径添加到环境变量。打开用户个性化配置文件
vim ~/.bashrc
将以下内容追加到文件末尾。
1 | # Hadoop |

使环境变量生效
source ~/.bashrc

验证hadoop环境变量是否正确,出现如下Hadoop版本,表示配置正确
hadoop version
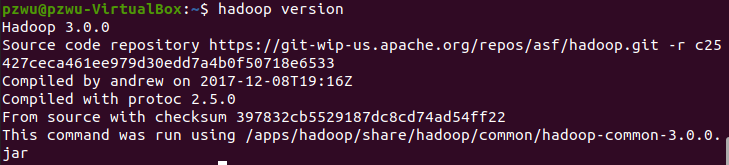
至此,单机Hadoop安装完成
5.实现伪分布式
接下来对Hadoop进行配置,以实现伪分布式。伪分布式是在一台机器上模拟一个只有一个节点的集群。
首先切换到Hadoop配置目录下。
cd /apps/hadoop/etc/hadoop

(1) 修改配置文件hadoop-env.sh
vim hadoop-env.sh
去掉54行的注释,并修改为
export JAVA_HOME=/apps/java

(2) 修改配置文件core-site.xml
vim core-site.xml
添加下面配置到
1 | <property> |
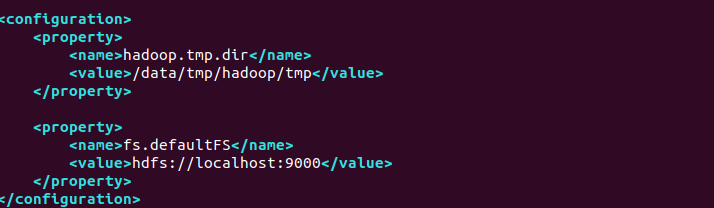
两项配置
- hadoop.tmp.dir,配置Hadoop处理过程中,临时文件的存储位置。这里的目录/data/tmp/hadoop/tmp需要自己创建。

- fs.defaultFS,配置HDFS文件系统的地址和端口。
(3)修改配置文件hdfs-site.xml
vim hdfs-site.xml
添加下面配置到
1 | <property> |
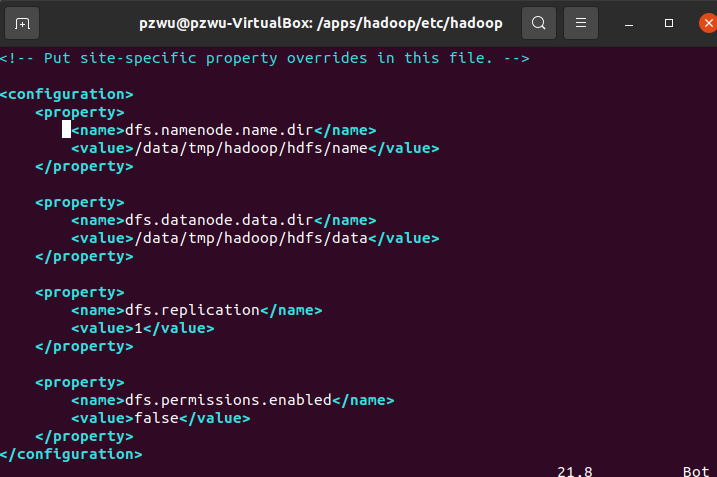
配置项说明:
dfs.namenode.name.dir,配置NameNode元数据存储位置;
dfs.datanode.data.dir,配置DataNode元数据存储位置;
dfs.replication,配置每份数据备份数,由于目前我们使用1台节点,所以,设置为1,如果设置为2的话,运行会报错。
dfs.permissions.enabled,配置hdfs是否启用权限认证,我们选择否。
另外/data/tmp/hadoop/hdfs目录,需要自己创建
mkdir -p /data/tmp/hadoop/hdfs

(4) 修改配置文件workers
vim workers
将集群中slave角色的节点的主机名,添加进workers文件中。目前只有一台节点,所以workers文件内容为:
localhost
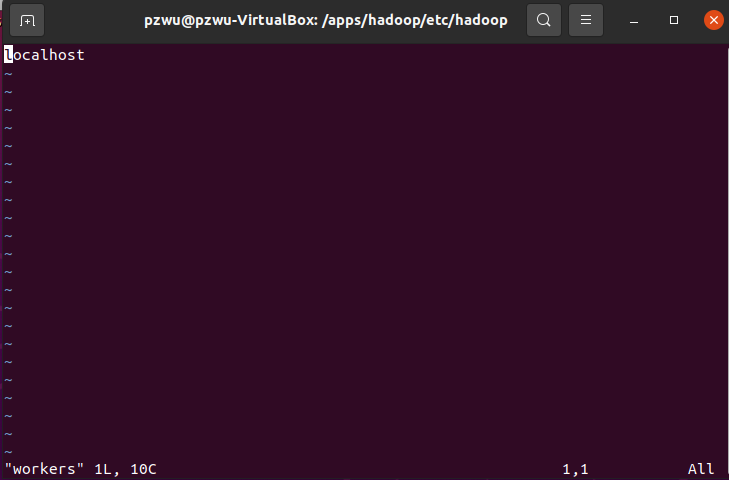
无需配置
6.格式化HDFS
格式化HDFS文件系统。执行:
hadoop namenode -format

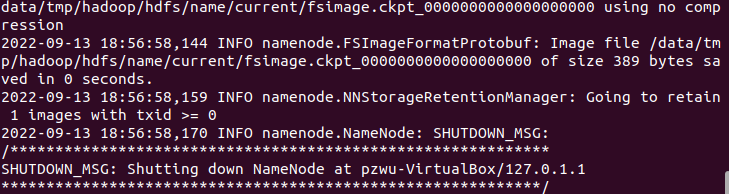
如果没有报错,说明格式化成功。
注:警告无/apps/hadoop/logs 自动创建该文件
7.测试HDFS
切换目录到/apps/hadoop/sbin目录下,启动Hadoop的hdfs相关进程。
cd /apps/hadoop/sbin/

./start-dfs.sh

这里只会启动HDFS相关进程。
输入jps查看HDFS相关进程是否已经启动。
jps

可以看到启动了三个进程NameNode, DataNode和SecondaryNameNode。
注:jps(Java Virtual Machine Process Status Tool)是java提供的一个显示当前所有java进程pid的命令。
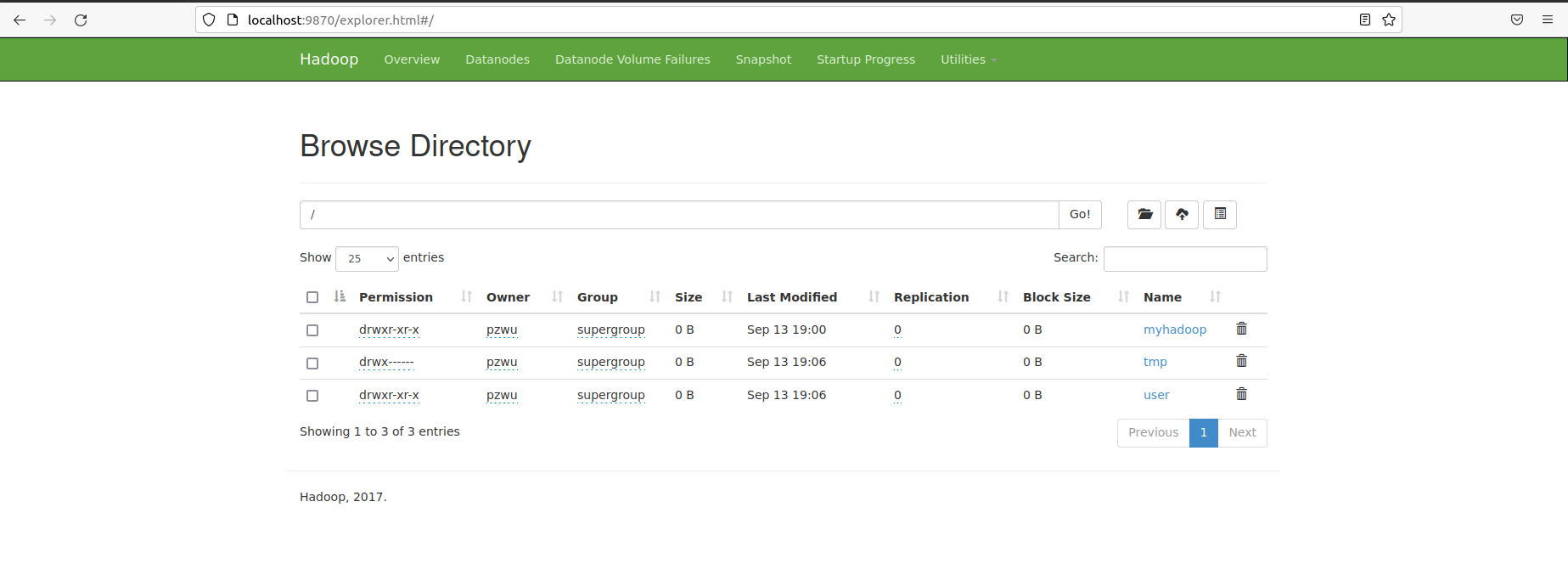
进一步验证HDFS运行状态。先在HDFS上创建一个目录。
hadoop fs -mkdir /myhadoop

执行下面命令,查看目录是否创建成功。
hadoop fs -ls /

8.配置MapReduce
再次切换到Hadoop配置文件目录
cd /apps/hadoop/etc/hadoop

(1) 修改配置文件mapred-site.xml
vim mapred-site.xml

将mapreduce相关配置,添加到
1 | <property> |
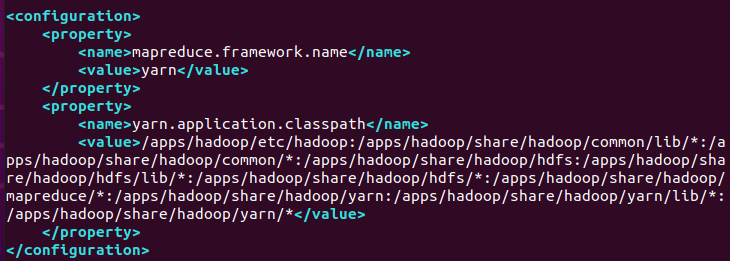
这里指定mapreduce任务处理所使用的框架。
(2) 修改配置文件yarn-site.xml
vim yarn-site.xml

将yarn相关配置,添加到
1 | <property> |
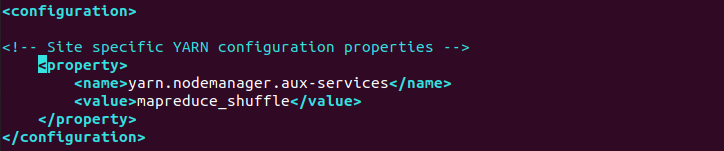
配置NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序。
启动计算层面相关进程,切换到Hadoop启动目录,执行以下命令启动Yarn。
cd /apps/hadoop/sbin/

./start-yarn.sh

输入jps,查看当前运行的进程,多了ResourceManager和NodeManager,算上jps,一共六个进程。
jps

9.执行测试
切换到/apps/hadoop/share/hadoop/mapreduce目录下。
cd /apps/hadoop/share/hadoop/mapreduce

在该目录下跑一个mapreduce程序,来检测一下Hadoop是否能正常运行。
在该目录下跑一个mapreduce程序,来检测一下Hadoop是否能正常运行。
这个程序是计算数学中的pi值。没有报错,表示程序已正常运行,Hadoop已正确安装的。

三、Web界面
1.Hadoop Web界面
在浏览器中访问http://localhost:8088 可以查看Hadoop集群,节点及任务相关信息。
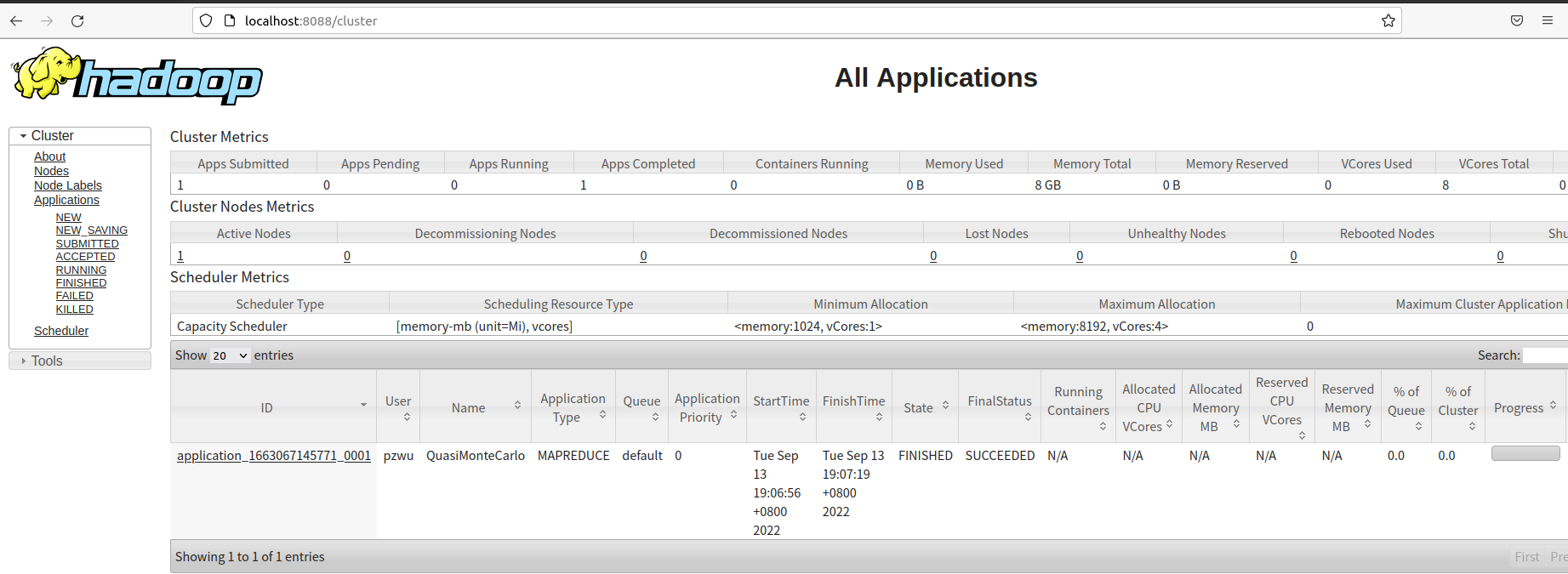
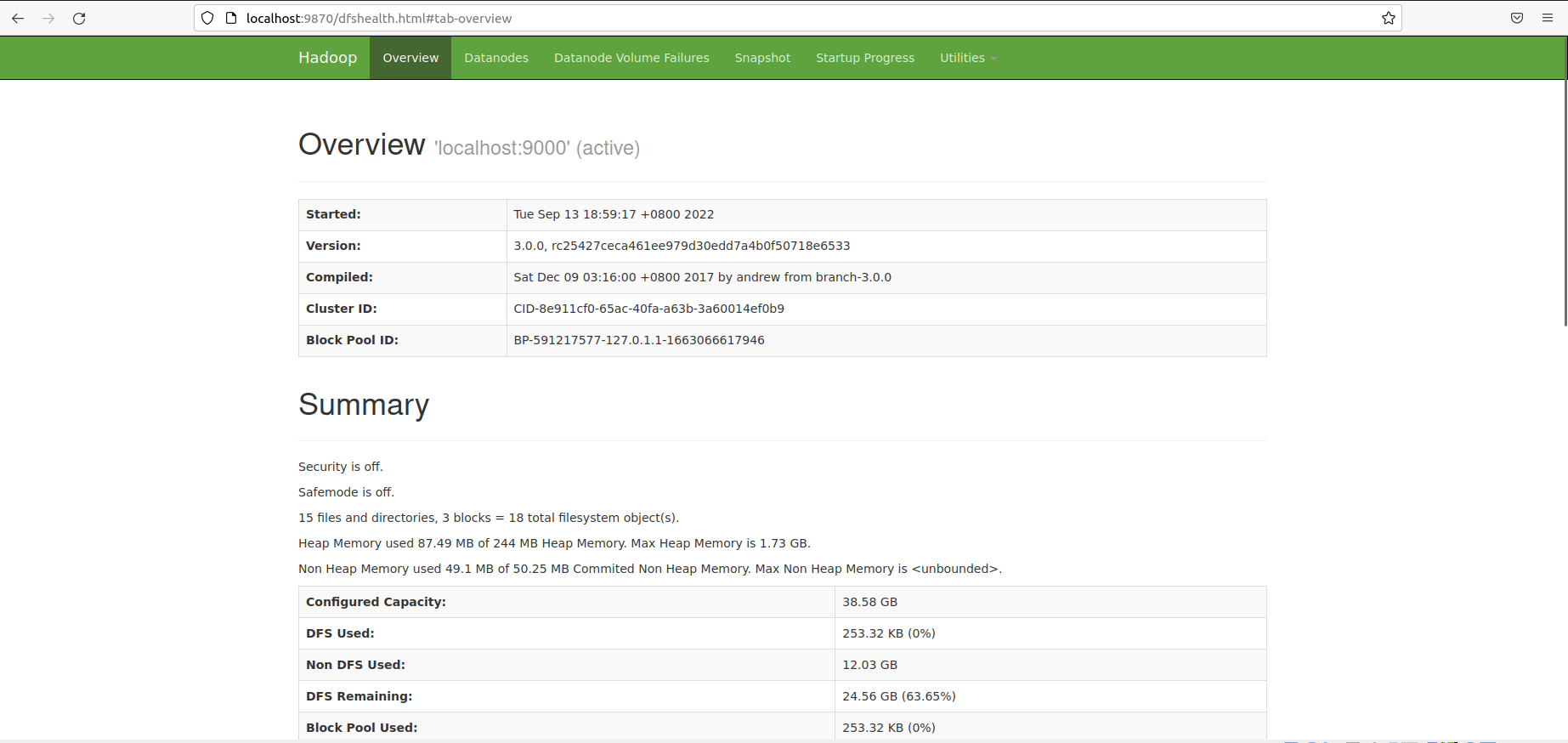
2.HDFS Web界面
在浏览器中访问http://localhost:8088 可以查看Hadoop集群,节点及任务相关信息。