在Eclipse中开发MapReduce程序WordCount,来统计词频
一、Hadoop数据类型;二、自定义数据类型;三、自定义分区函数;四、 命令行运行MapReduce程序
准备数据文件
在HDFS上创建文件夹/input/wordcount
1
| hadoop fs -mkdir -p /input/wordcount
|

在/data目录下创建文件testfile,
并写入以下内容
1
2
3
4
5
| hello big data
hello hadoop
hello hdfs
|
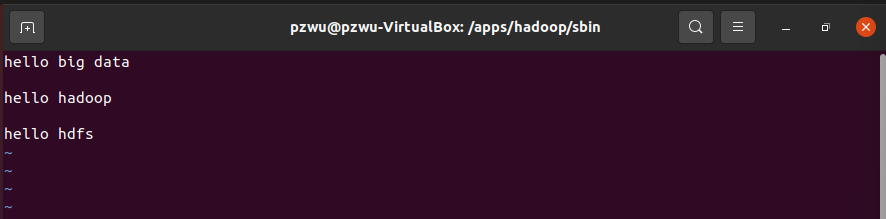
将/data/testfile上传到HDFS上的/input/wordcount目录。
1
| hadoop fs -put /data/testfile /input/wordcount
|
我们统计文件/input/wordcount/testfile出现的词的词频。
准备jar包
在~/big_data_tools目录下创建文件夹hadoop3libs
1
| mkdir ~/big_data_tools/hadoop3libs
|

将/apps/hadoop/share/hadoop目录下的common,hdfs,mapreduce,yarn 4个子目录中的jar文件以及这4个子目录下lib文件夹中的所有jar文件复制到hadoop3lib中。这些jar文件将作为外部的jar文件添加到统计词频的工程中。
完成代码
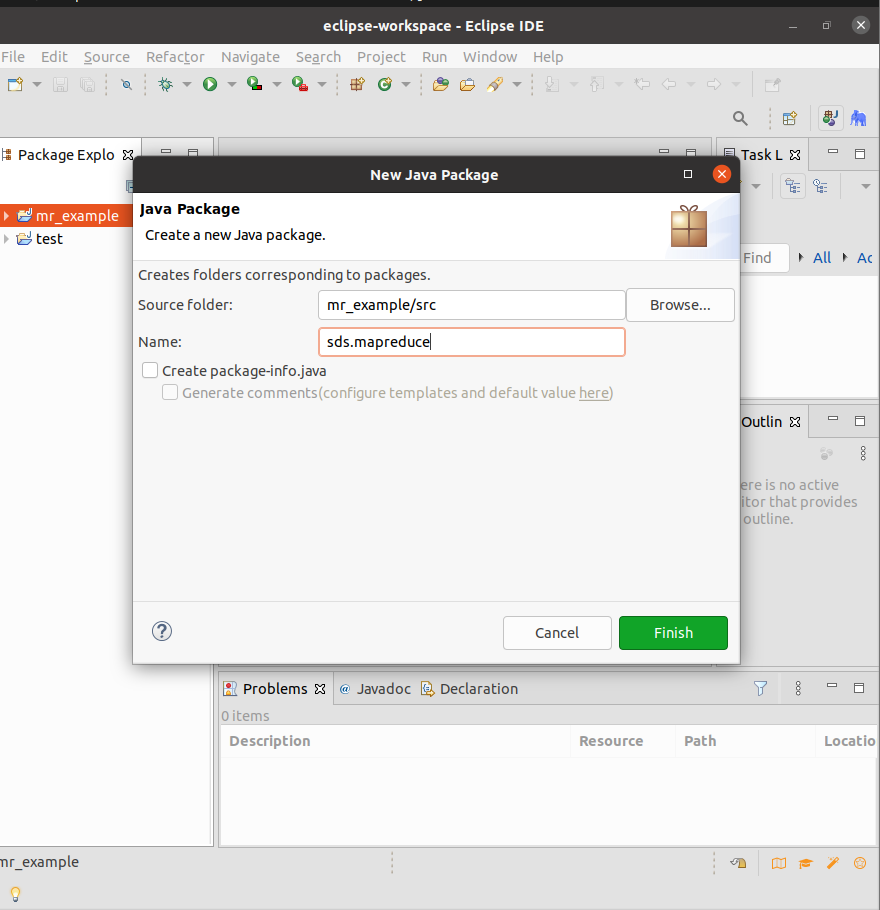
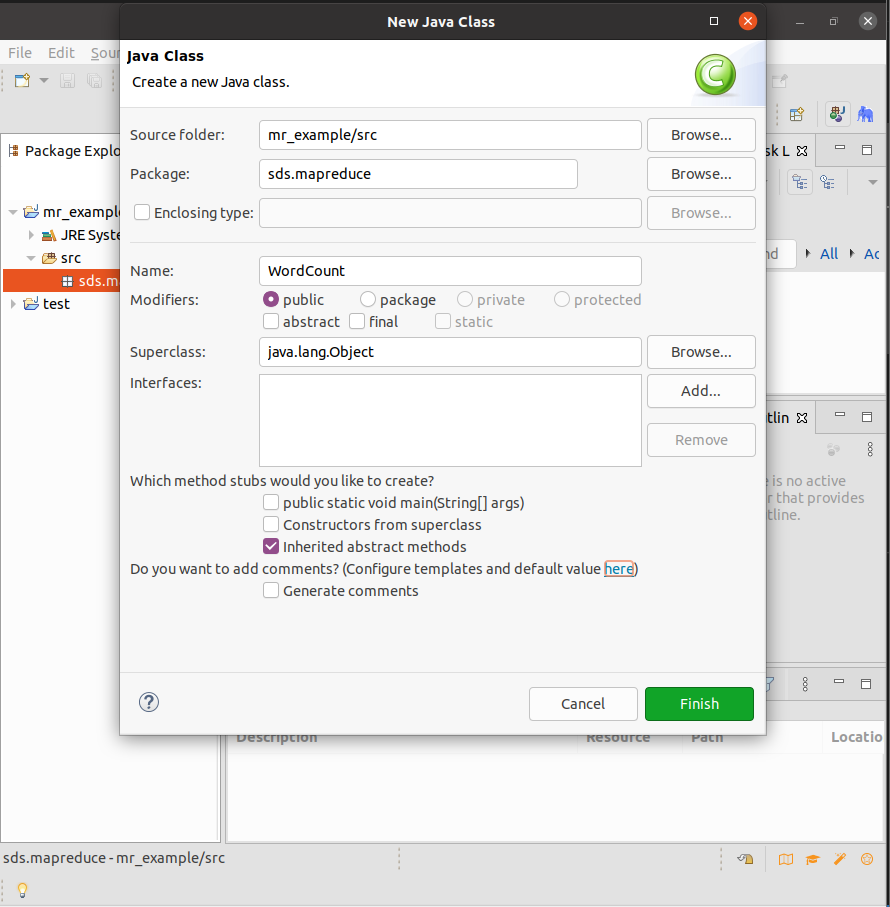
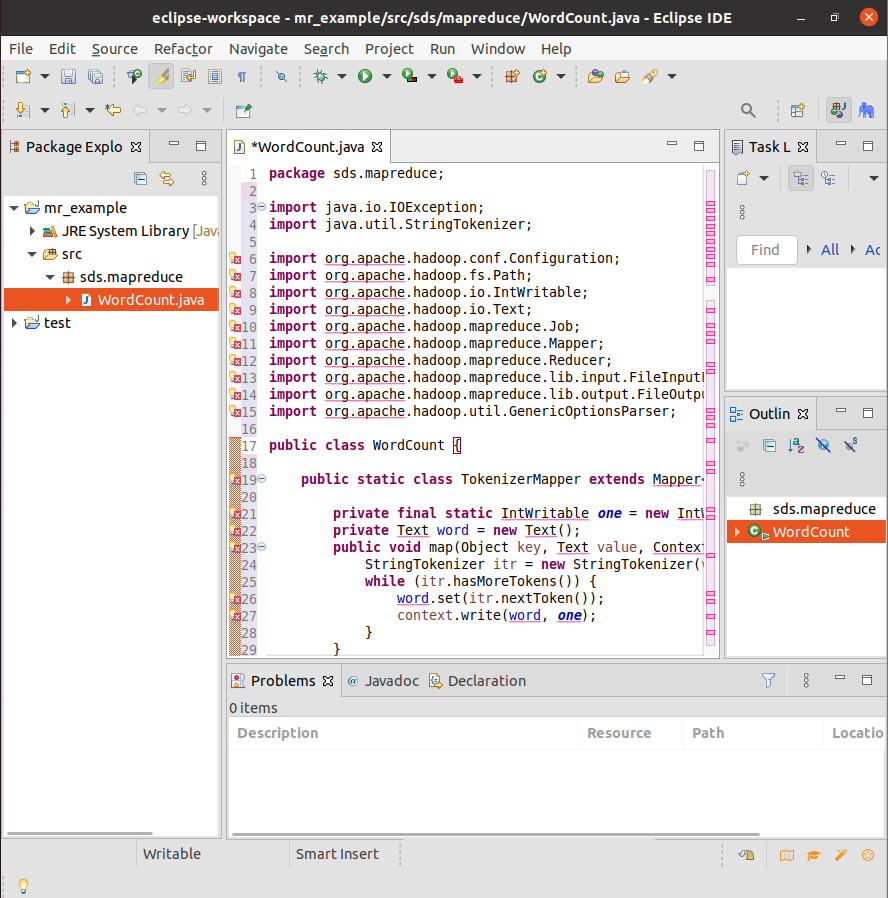
创建Project【mr_example】,在项目中创建Package【sds.mapreduce】,然后创建Class【WordCount】,将在中间窗口中自动打开WordCount.java文件,删除其中的代码,将下面的代码复制其中并保存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| package sds.mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
|
添加外部jar文件
在Package Explorer工程名mr_example上点击右键,选择【Build Path】=>【Configure Build Path…】。
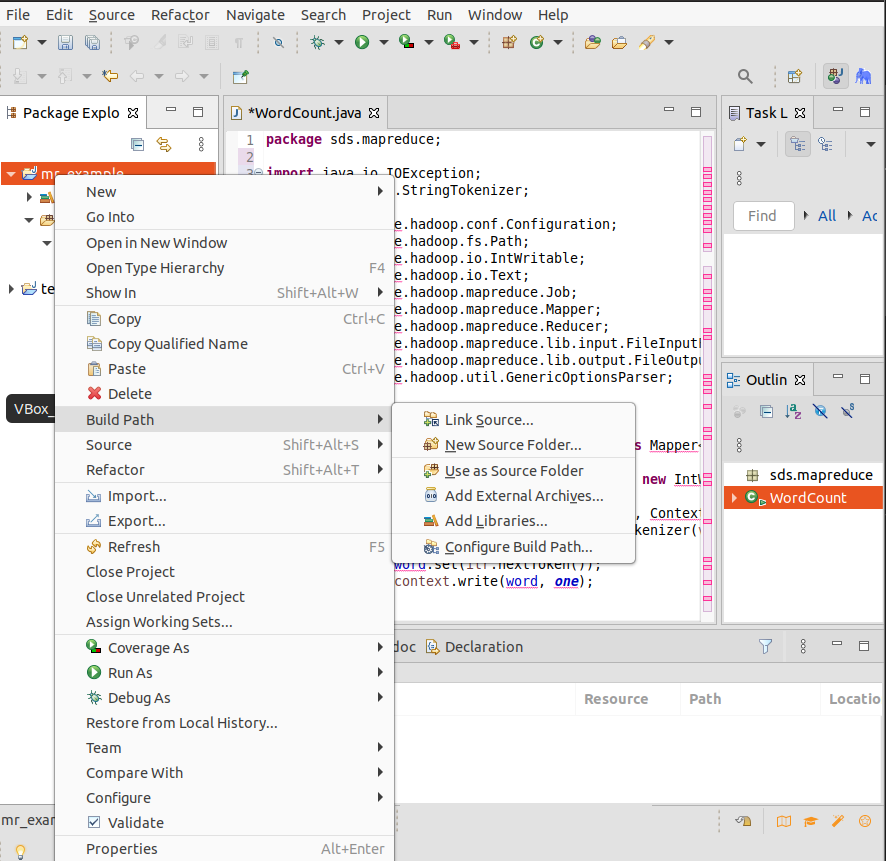
在【Java Build Path】对话框中,选择【Libraries】标签,点击右侧的【Add External JARs…】按钮。
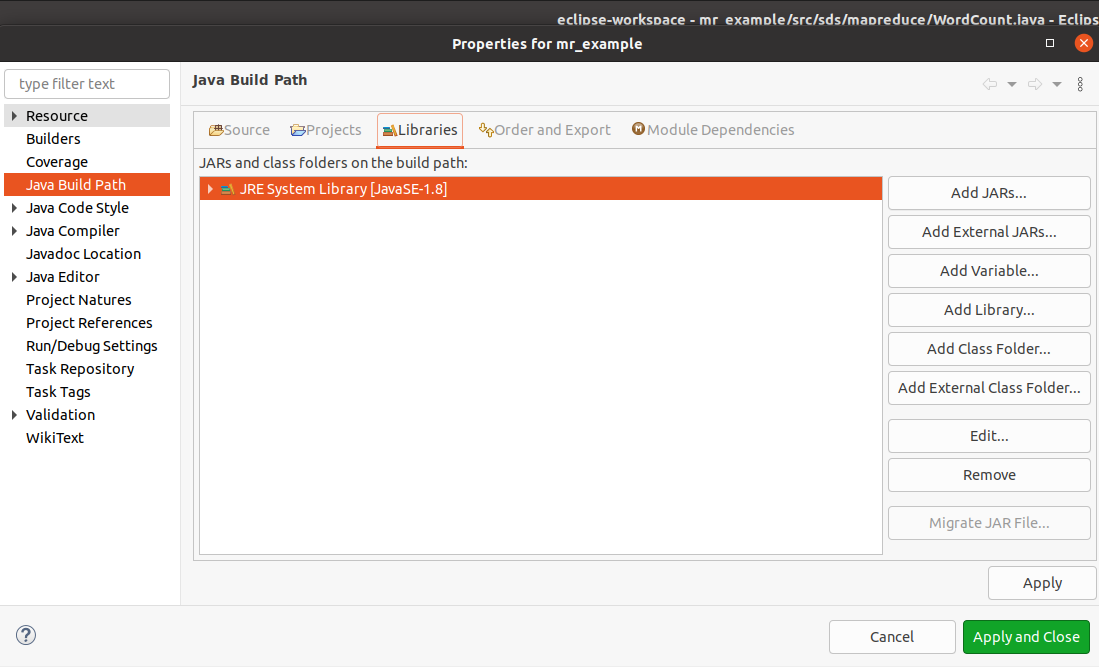
在弹出的JAR文件选择窗口,切换到目录~/big_data_tools/hadoop3libs,全选目录中的JAR文件。点击【Open】。
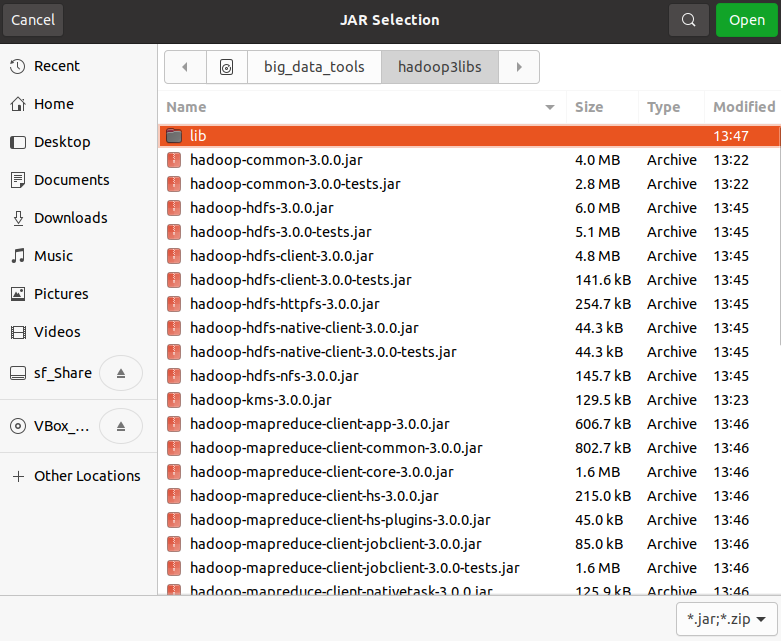
回到【Java Build Path】对话框,点击【Apply and Close】,完成添加jar包。
运行代码
因为代码中设置了从命令行获取参数,所以运行时,需要提供参数的值。在Eclipse中点击右键,选择【Run As】=>【Run Configurations…】,
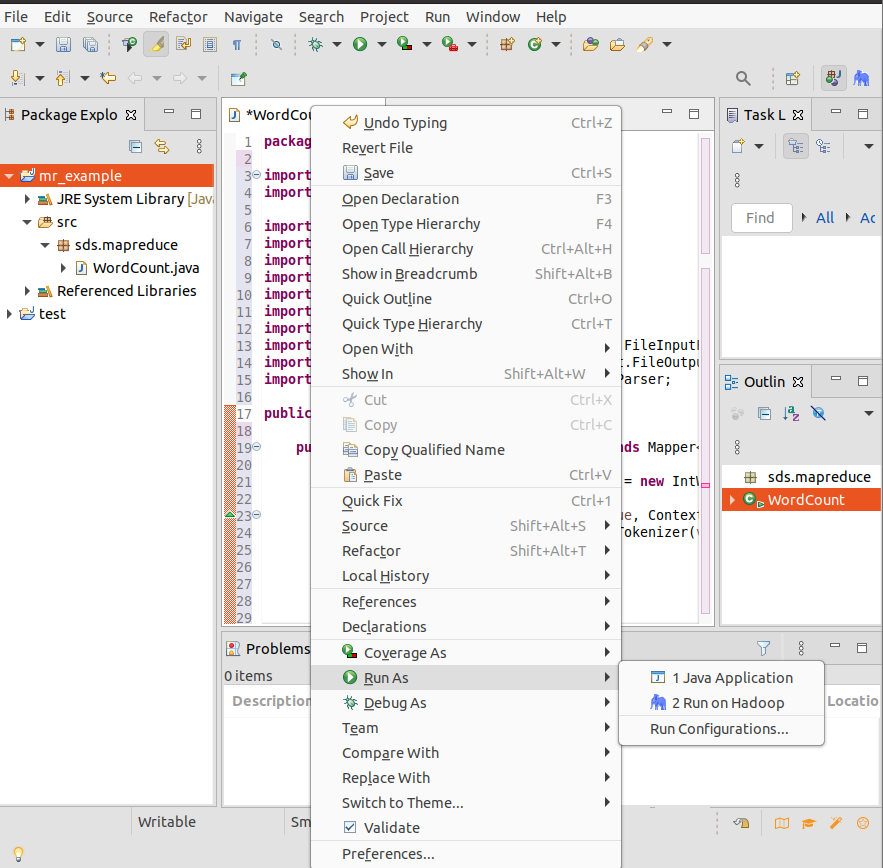
在弹出的【Run configurations】对话框中,从左边的列表中选择我们要运行的Java Application 【WordCount】。然后在右边选择【Arguments】标签,在【Program arguments】中提供需要的参数值,也就是我们要统计词频的输入文件和存放结果的输出目录,各个参数用空格隔开。
1
| hdfs://localhost:9000/input/wordcount/testfile hdfs://localhost:9000/output/wordcount
|
注意如果输出目录在HDFS上已存在,需要先删除,否则会报错。这里HDFS上的地址需要写全,前面需要加上hdfs://localhost:9000/。设置好以后点击【Run】。
删除输出目录命令
1
| hadoop fs -rm -r /output/wordcount
|
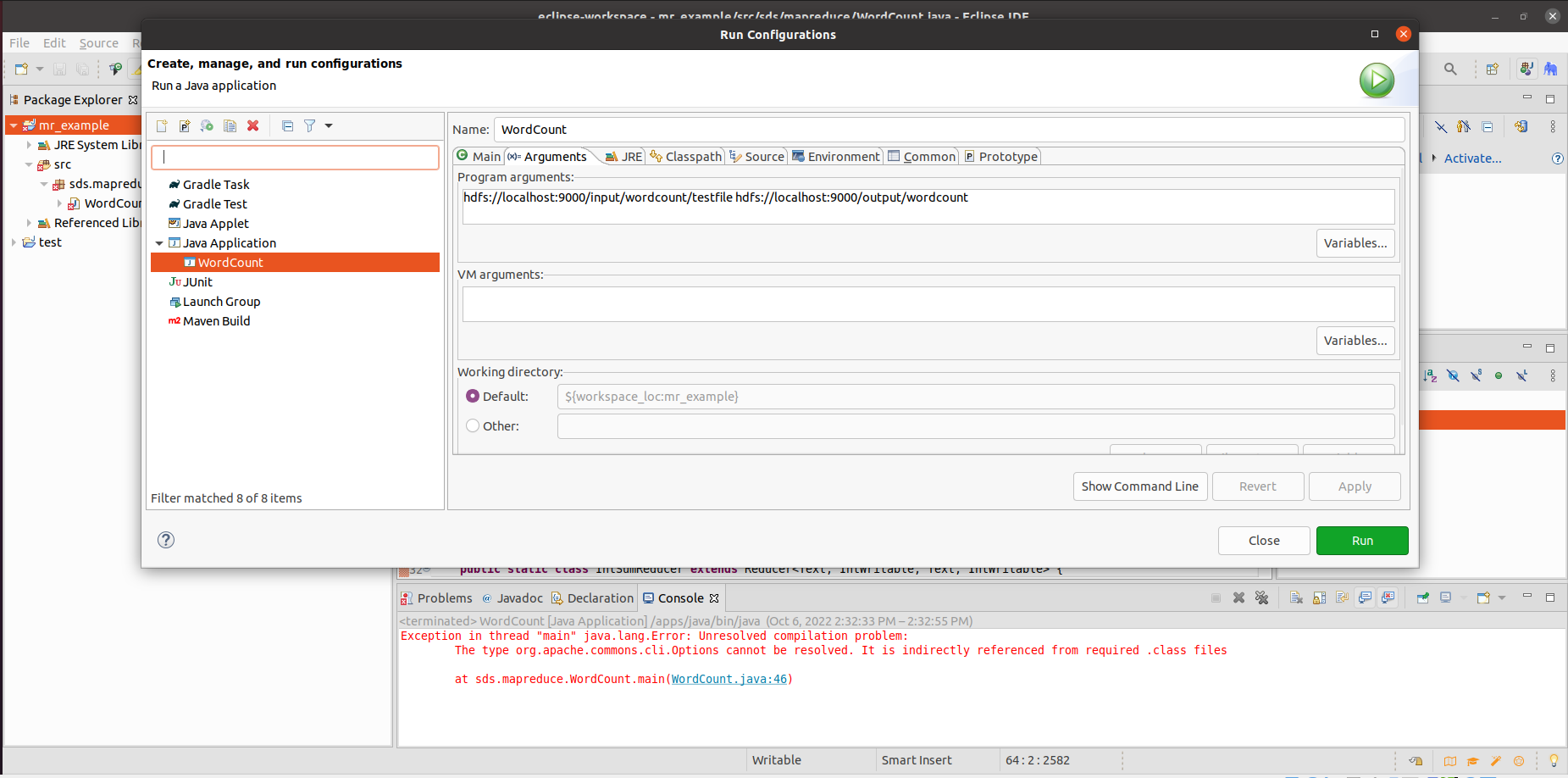
运行结束以后,我们可以在【Project Explorer】中的【DFS Locations】中看到,在/output目录下生成了子目录/output/wordcount,双击打开其中的文件part-r-00000,如果内容是我们预期的词频统计结果,说明我们程序运行成功。
Hadoop程序开发
本节练习Hadoop数据类型的用法,学习如何自定义Hadoop类并用这些类来编写MapReduce程序。
一、Hadoop数据类型
为了解决数据在集群节点之间传输的问题,Hadoop采用了Java中的序列化和反序列化概念。在Hadoop中,位于org.apache.hadoop.io包中的Writable接口是Hadoop序列化格式的实现。Writable接口实现了很多Hadoop数据类型,如表1所示,它们将Java的基本数据类型和一些常用的类(如字符串,数组,集合等)序列化,然后在节点之间传递,然后在目的地反序列化。
| 数据类型 |
Hadoop数据类型 |
Java数据类型 |
| 布尔型 |
BooleanWritable |
boolean |
| 整型 |
IntWritable |
int |
| 长整型 |
LongWirteble |
long |
| 浮点数 |
FloatWritable |
float |
| 双字节数值 |
DoubleWritable |
double |
| 单字节数值 |
ByteWritable |
byte |
| 使用UTF8格式存储的文本 |
Text |
String |
| 数组 |
ArrayWritable |
Array |
| map集合 |
MapWritable |
map |
| 空引用 |
NullWritable |
null |
表1 Hadoop和Java数据类型
除char类型以外,每个Java基本类型的Writable封装,其类的内部都包含一个对应基本类型的成员变量value,get()和set()方法就是用来对该变量进行取值/赋值操作的。这些类型都位于org.apache.hadoop.io包中。
下面的例子演示了基本数据类型的使用,在项目【mr_example】的包【sds.mapreduce】中创建类【HadoopDataType】,删除其中的代码,将下面的代码复制其中并保存。运行并观察结果。模仿代码,探究其它数据类型的用法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| package sds.mapreduce;
import org.apache.hadoop.io.ArrayWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
/** hadoop数据类型 */
public class HadoopDataType {
/** 使用IntWritable */
public static void testIntWritable() {
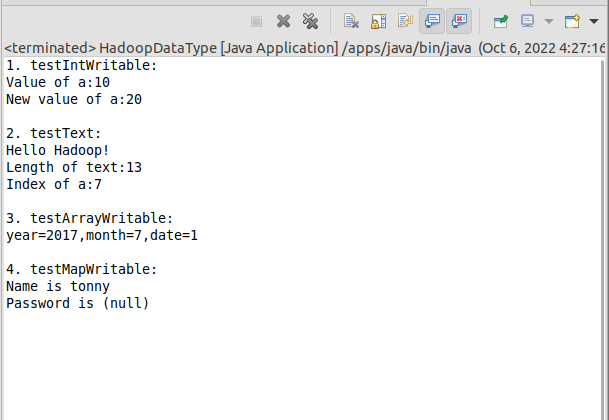
System.out.println("1. testIntWritable:");
IntWritable a = new IntWritable(10);
System.out.println(String.format("Value of a:%s", a.get()));
a.set(20);
System.out.println(String.format("New value of a:%s\n", a.get()));
}
/** 使用hadoop的Text类型数据 */
public static void testText() {
System.out.println("2. testText:");
Text text = new Text("Hello Hadoop!");
System.out.println(text.toString());
System.out.println(String.format("Length of text:%d",text.getLength()));
System.out.println(String.format("Index of a:%d\n",text.find("a")));
}
/** 使用ArrayWritable */
public static void testArrayWritable() {
System.out.println("3. testArrayWritable:");
ArrayWritable arr = new ArrayWritable(IntWritable.class);
IntWritable year = new IntWritable(2017);
IntWritable month = new IntWritable(07);
IntWritable date = new IntWritable(01);
arr.set(new IntWritable[] { year, month, date });
System.out.println(String.format("year=%d,month=%d,date=%d\n",
((IntWritable) arr.get()[0]).get(),
((IntWritable) arr.get()[1]).get(),
((IntWritable) arr.get()[2]).get()));
}
/** 使用MapWritable */
public static void testMapWritable() {
System.out.println("4. testMapWritable:");
MapWritable map = new MapWritable();
Text k1 = new Text("name");
Text v1 = new Text("tonny");
Text k2 = new Text("password");
map.put(k1, v1);
map.put(k2, NullWritable.get());
System.out.println(String.format("Name is %s",map.get(k1).toString()));
System.out.println(String.format("Password is %s",map.get(k2).toString()));
}
public static void main(String[] args) {
testIntWritable();
testText();
testArrayWritable();
testMapWritable();
}
}
|
运行结果如下图所示
二、自定义数据类型
一般自定义数据类型要实现Writable接口(实现其方法write()和readFields()),因为数据在网络传输或者进行永久性存储的时候,需要序列化和反序列化。如果该数据类型要作为主键使用或者要进行比较大小的操作,则要实现WritableComparable接口(实现其方法write(),readFields()和CompareTo() )。
步骤:
(1)创建类实现WritableComparable或者Writable
(2)根据需要定义属性,生成get/set函数
(3)构造函数:空参,带参数
(4)序列化和反序列方法实现
- 重写write方法并添加逻辑以写入所有字段值(就是调用基本类型的write方法)
- 重写readFields方法从输入流读取所有字段值
(5)重写compareTo方法并实现自定义数据类型排序的逻辑
接下来创建一个类,实现矩形按面积升序排序。数据文件格式如下,两列分别为矩形的长和宽,保存到文件/data/Rectangle.txt中。
在HDFS上创建目录/input/sort,并将数据文件上传其中。
1
| hadoop fs -mkdir /input/sort
|
1
| hadoop fs -put /data/Rectangle.txt /input/sort
|
在项目【mr_example】的包【sds.mapreduce】中创建类【RectangleWritable】,将下面的代码复制其中并保存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| package sds.mapreduce;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class RectangleWritable implements WritableComparable <RectangleWritable> {
int length, width;
public int getLength() {
return length;
}
public void setLength(int length) {
this.length = length;
}
public int getWidth() {
return width;
}
public void setWidth(int width) {
this.width = width;
}
public RectangleWritable() {
super();
}
public RectangleWritable(int length, int width) {
super();
this.length = length;
this.width = width;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(length);
out.writeInt(width);
}
@Override
public void readFields(DataInput in) throws IOException {
this.length = in.readInt();
this.width = in.readInt();
}
@Override
public int compareTo(RectangleWritable o) {
if (this.getLength() * this.getWidth() > o.getLength() * o.getWidth())
return 1;
if (this.getLength() * this.getWidth() < o.getLength() * o.getWidth())
return -1;
return 0;
}
}
|
三、自定义分区函数
在项目【mr_example】的包【sds.mapreduce】中创建类【RectangleSort】,将下面的代码复制其中并保存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
| package sds.mapreduce;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class RectangleSort {
static final String INPUT_PATH = "hdfs://localhost:9000/input/sort/Rectangle.txt";
static final String OUTPUT_PATH = "hdfs://localhost:9000/output/rectangle";
public static void main(String[] args) throws Throwable, URISyntaxException {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
Path outpath = new Path(OUTPUT_PATH);
if (fileSystem.exists(outpath)) {
fileSystem.delete(outpath, true);
}
Job job = Job.getInstance(conf, "RectangleSort");
job.setJarByClass(RectangleSort.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(RectangleWritable.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
job.setOutputFormatClass(TextOutputFormat.class);
job.setPartitionerClass(MyPatitioner.class);
job.setNumReduceTasks(2);
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, RectangleWritable, NullWritable> {
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
String[] splites = v1.toString().split(" ");
RectangleWritable k2 = new RectangleWritable(
Integer.parseInt(splites[0]), Integer.parseInt(splites[1]));
context.write(k2, NullWritable.get());
};
}
static class MyReducer extends Reducer<RectangleWritable, NullWritable, IntWritable, IntWritable> {
protected void reduce(RectangleWritable k2, Iterable<NullWritable> v2s,Context context) throws IOException, InterruptedException {
context.write(new IntWritable(k2.getLength()),
new IntWritable(k2.getWidth()));
};
}
}
class MyPatitioner extends Partitioner<RectangleWritable, NullWritable> {
@Override
public int getPartition(RectangleWritable k2, NullWritable v2, int numReduceTasks) {
if (k2.getLength() == k2.getWidth()) {
return 0;
} else
return 1;
}
}
|
运行代码回答以下问题:
Java泛型的用法
声明:
1
2
3
4
5
6
7
|
public <T> String commonMethod(String name,T t){
String res = "";
res += name +"-"+ t;
System.out.println("普通泛型方法 : "+res);
return res;
}
|
调用:
1
2
3
4
5
6
7
8
9
10
11
| public static void main(String[] args) {
GenericMethod genericMethod = new GenericMethod();
String commonRes01 = genericMethod.commonMethod("001", "bb");
System.out.println(commonRes01);
String commonRes02 = genericMethod.commonMethod("002", 100);
System.out.println(commonRes02);
String commonRes03 = genericMethod.commonMethod("003", true);
System.out.println(commonRes03);
System.out.println("==================");
}
|
静态泛型方法
声明
1
2
3
4
5
6
7
|
public static <T,E> String staticMethod(String name,T t,E e){
String res = "";
res += name +"-"+ t +"-"+ e;
System.out.println("静态泛型方法 : "+res);
return res;
}
|
调用
1
2
3
4
5
6
7
8
9
10
11
| public static void main(String[] args) {
String staticRes01 = GenericMethod.staticMethod("001", "aa", "bb");
System.out.println(staticRes01);
String staticRes02 = GenericMethod.staticMethod("002", 100, 'c');
System.out.println(staticRes02);
String staticRes03 = GenericMethod.staticMethod("003", 12.05d, false);
System.out.println(staticRes03);
System.out.println("==================");
}
|
声明
1
2
3
4
5
6
7
| public class GenericMethod {
public <A> void argsMethod(A ... args){
for (A arg : args) {
System.out.println(arg);
}
}
|
调用
1
2
3
4
5
6
| public class GenericMethodApplication {
public static void main(String[] args) {
genericMethod.argsMethod(1,2,300,400,500,600);
System.out.println("==================");
}
|
解释分区函数
在RectangleSort中规定了指定输出文件的格式化类分区和需要几个reducer类进行工作
在MyPatitioner中重新规定了分区,将正方形和长方形在任务0,1中进行了汇总
解释代码结果
文件夹中有0、1两个文件,文件分别保存正方形和长方形。
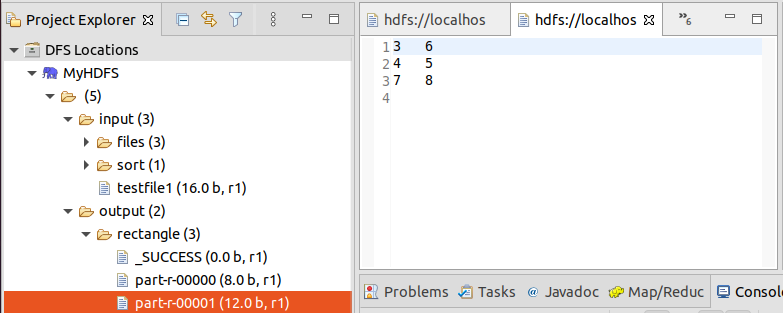
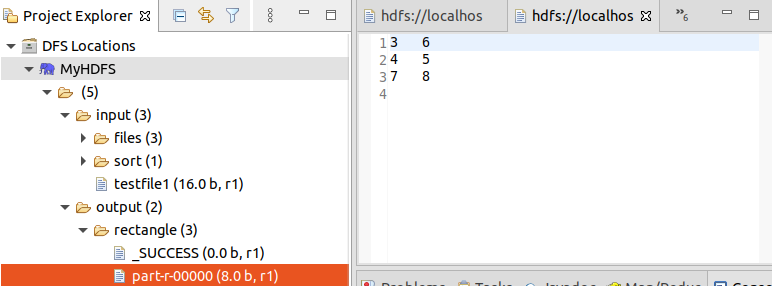
四、 命令行运行MapReduce程序
在Eclipse中运行MapReduce程序,是用本地的Hadoop类库来运行程序,并没有把jar包发送到Hadoop集群上去运行,所以Hadoop集群中不用启动YARN也可以运行,web管理页面(http://localhost:8088)也看不到作业信息。在集群中让程序分布式运行,需要把程序保存成jar包,用hadoop命令运行。
导出jar包
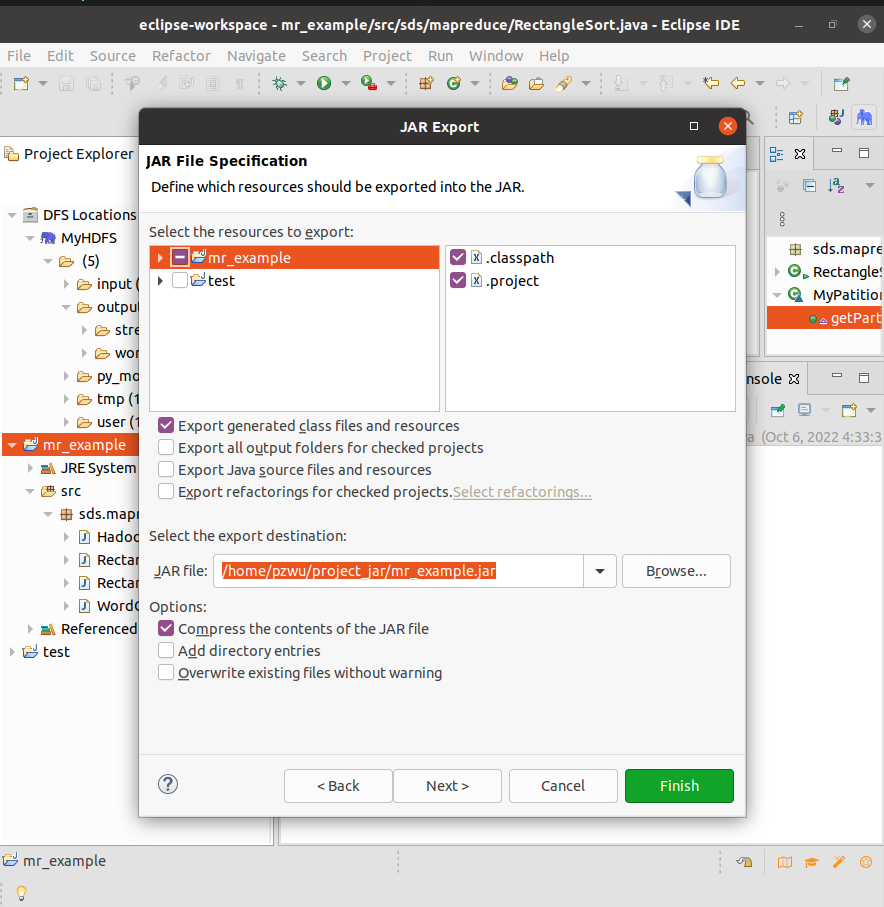
在自己家目录下创建~/project_jar目录用于保存导出的jar包。在Eclipse【Project Explorer】中,右键点击Project 【mr_example】,选择【Export…】
在弹出的【Export】对话框,选择【JAR file】,点击【Next】.
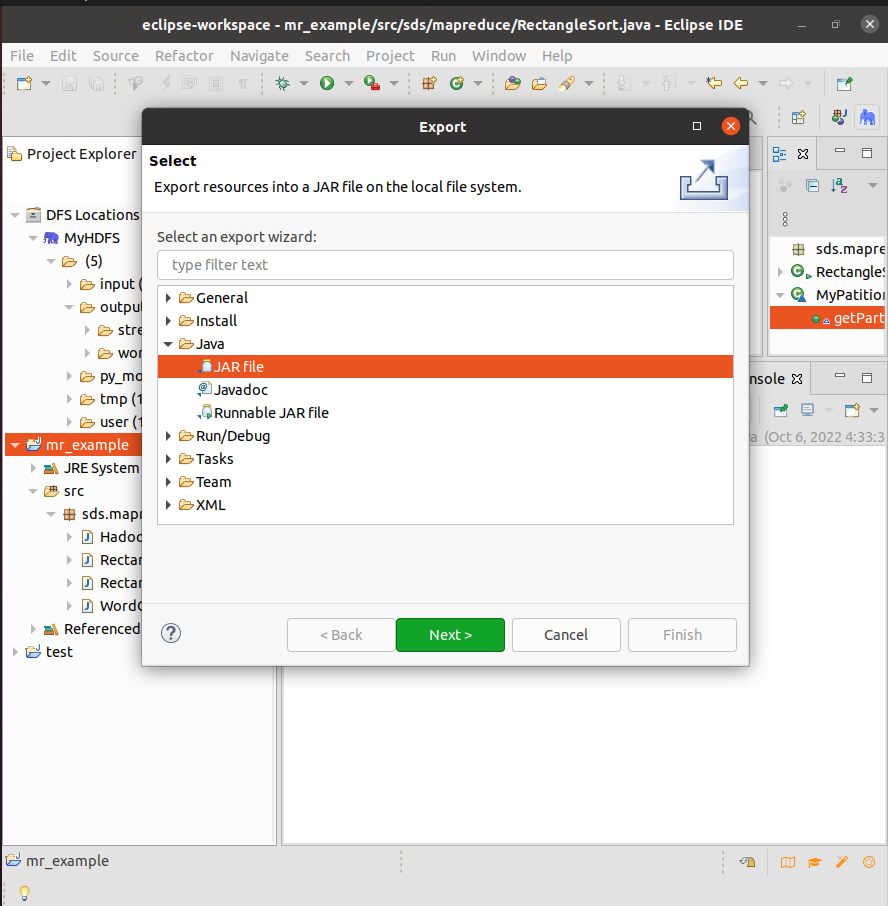
弹出【JAR Export】对话框,这里可以选择要导出的类以及设置保存目录。我们把导出目录设置为我们前面创建的目录/project_jar,其它选项保持默认值。点击【Finish】。可以在/project_jar 目录中看到导出的jar包mr_example.jar
命令行运行
使用以下命令,在集群上运行MapReduce程序
格式:
hadoop jar jarFile [mainClass] [Args]
- jarFile:jar包
- mainClass:指定运行的主类
- Args:其它参数
例如,运行WordCount,在终端中执行
hadoop jar ~/project_jar/mr_example.jar sds.mapreduce.WordCount /input/wordcount/testfile /output/wordcount
运行前检查一下,输出目录/output/wordcount是否已经存在,如果已经存在,需要先删除,否则会报错。

如果显示以下信息,说明运行成功。

从上面的日志信息可以看出提交任务的id为application_1665033338967_0001。打开Hadoop Web界面http://localhost:8088,所有提交到集群的任务都在列表中,通过job id,我们知道第一个就是我们刚才提交的WordCount任务。
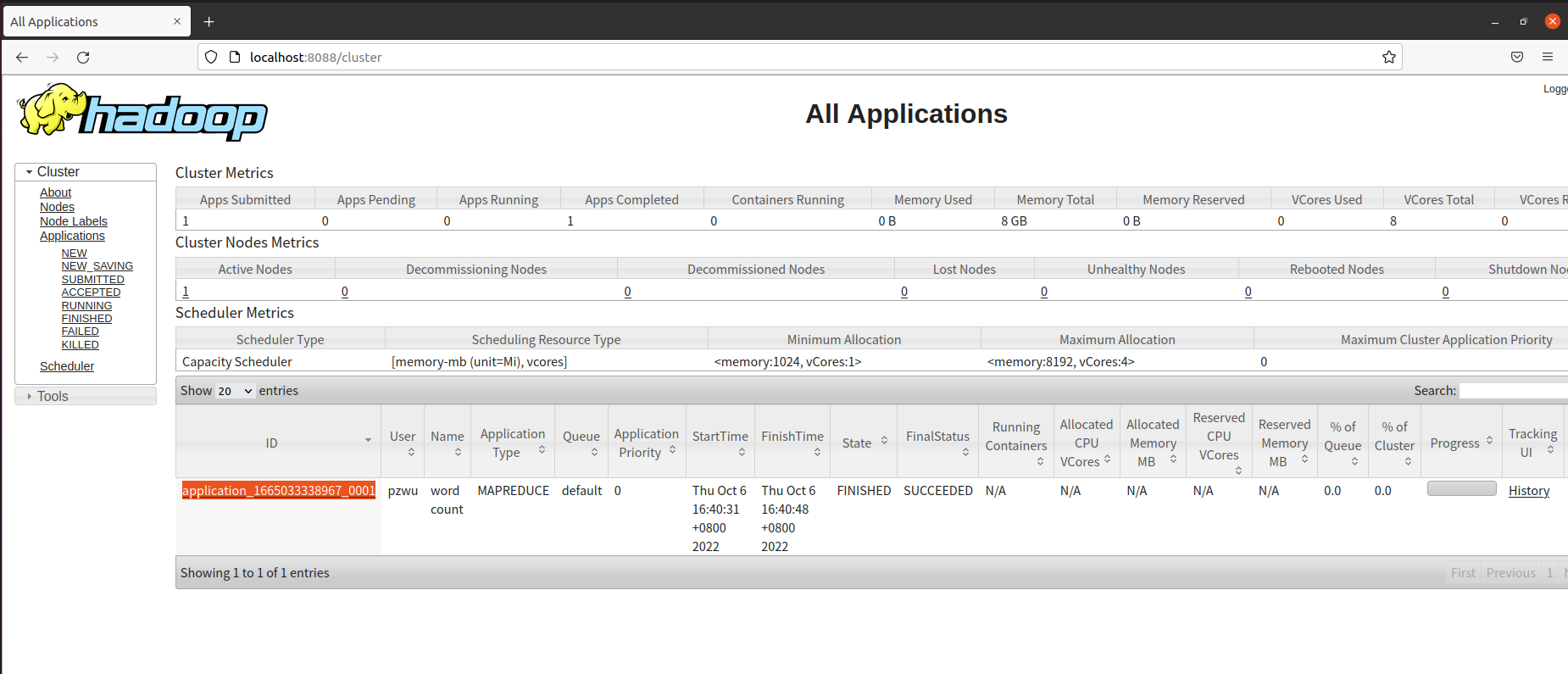
在任务列表中,点击ID,可以查看任务的具体信息。
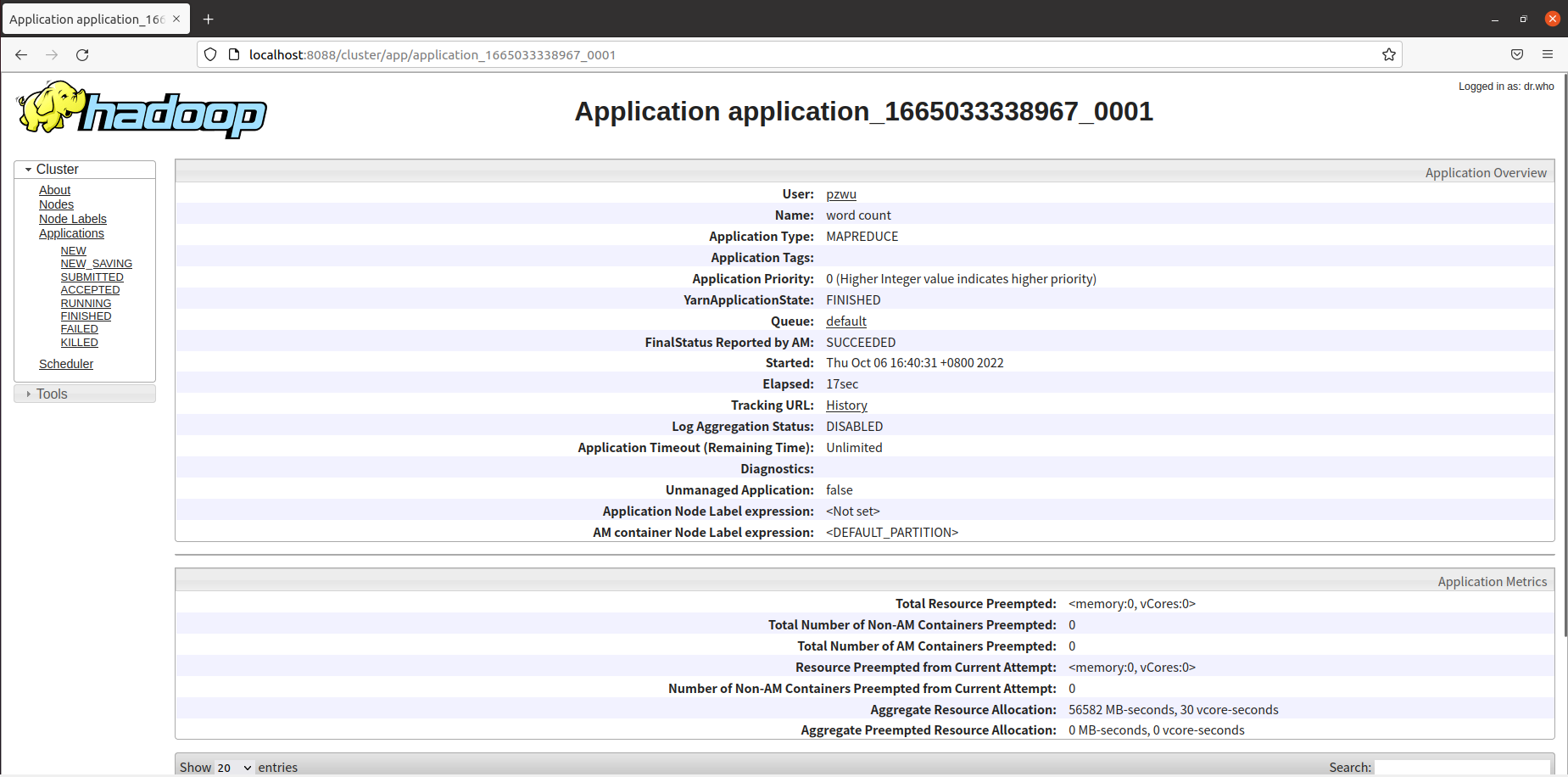
如果任务失败,可以在下方查看日志信息,查找错误原因。
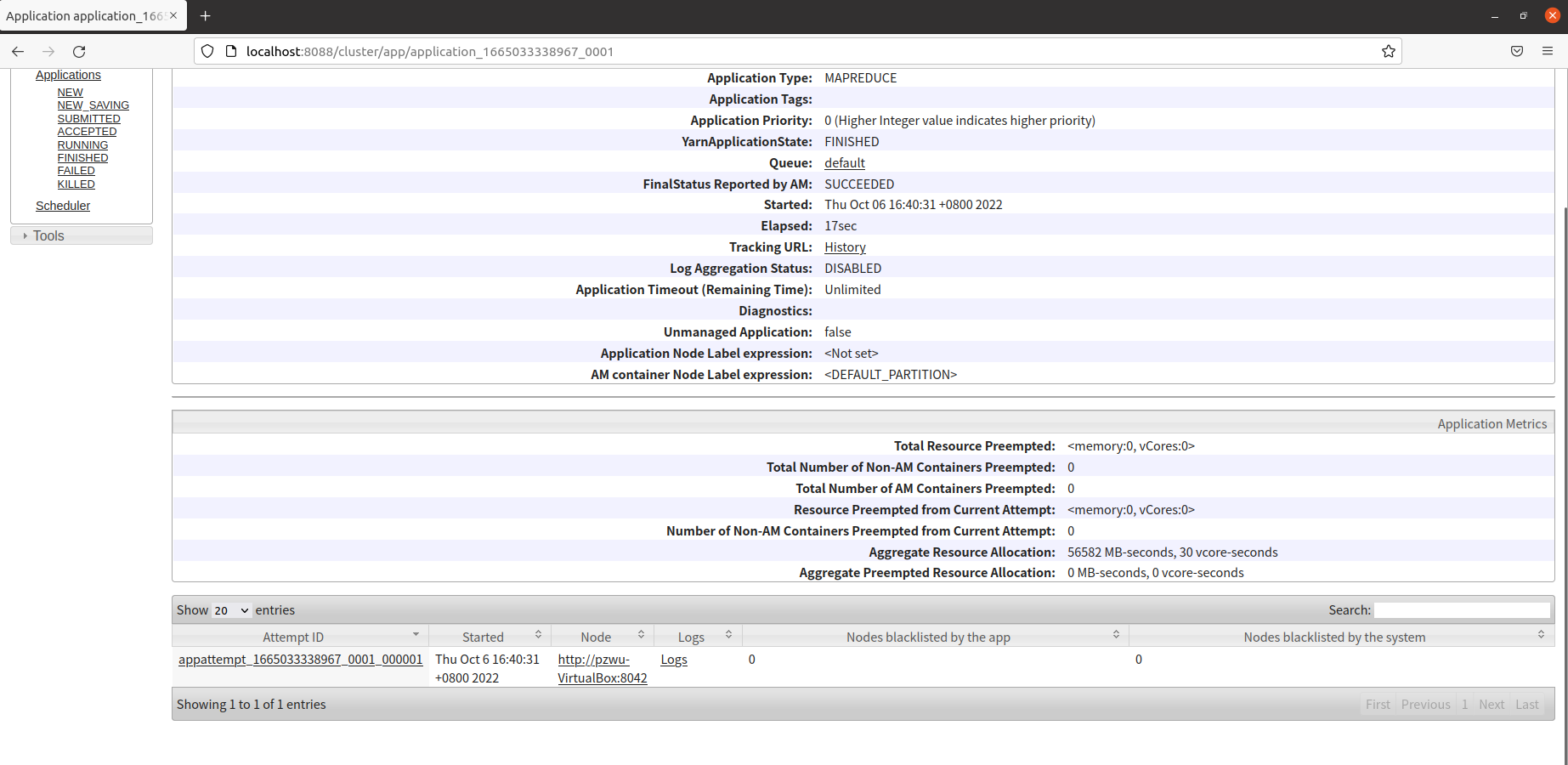
在终端中执行以下命令,可以查看程序运行结果。
1
| hadoop fs -cat /output/wordcount/*
|

练习:在命令行运行RectangleSort,并查看运行结果。
在命令行运行如下代码
1
| hadoop jar ~/project_jar/mr_example.jar sds.mapreduce.RectangleSort /input/sort/Rectangle.txt hdfs://localhost:9000/output/rectangle
|

运行结果如下:
