一、Java API ;二、将tsv文件数据存入HBase ;三、HBase 与MapReduce整合 ;四、Web UI
一、Java API 1. API介绍 HBase 主要包括 5 大类操作:HBase 的配置、HBase 表的管理、列族的管理、列的管理、数据操作等。
1)org.apache.hadoop.hbase.HBaseConfiguration
1 static Configuration conf = HBaseConfiguration.create();
2 ) org.apache.hadoop.hbase.client. HBaseAdmin
1 2 3 4 5 6 7 8 9 10 11 12 13 Connection conn = ConnectionFactory.createConnection(conf);HBaseAdmin admin = (HBaseAdmin) conn.getAdmin();if (admin.tableExists(tableName)) { System.out.println("table exists!" ); } else { HTableDescriptor tableDesc = new HTableDescriptor (TableName.valueOf(tableName)); for (String cf : columnFamilys) { HColumnDescriptor columnDescriptor = new HColumnDescriptor (cf); columnDescriptor.setMaxVersions(1 ); tableDesc.addFamily(columnDescriptor); } admin.createTable(tableDesc); }
3 ) org.apache.hadoop.hbase.HTableDescriptor
1 2 3 4 HTableDescriptor tableDesc = new HTableDescriptor (TableName.valueOf(tableName)); tableDesc.addFamily (new HColumnDescriptor("name"));// 增加列族 tableDesc.addFamily(new HColumnDescriptor("age")); tableDesc.addFamily(new HColumnDescriptor("gender"));
4 ) org.apache.hadoop.hbase.HColumnDescriptor
5 ) org.apache.hadoop.hbase.client.Table
1 2 3 Table table = conn.getTable(TableName.valueOf(tableName)) Delete delete = new Delete(Bytes.toBytes(rowkey)); table.delete(delete);
6 ) org.apache.hadoop.hbase.client.Put
1 2 3 Put p1 = new Put(Bytes.toBytes(rowkey)); p1.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(qualifer),Bytes.toBytes(data)); table.put(p1);
7 ) org.apache.hadoop.hbase.client.Get
1 2 Get get = new Get(Bytes.toBytes(rowkey)); Result result = table.get(get);
8 ) org.apache.hadoop.hbase.client.Result
1 2 3 Get get = new Get(Bytes.toBytes(rowkey)); Result result = table.get(get); System.out.println("Get: " + new string(result.getValue(columnFamily.getBytes(),qualifier.getBytes())));
9 ) org.apache.hadoop.hbase.client.Scan
1 2 3 Scan scan = new Scan(); scan.addFamily(Bytes.toBytes("columnFamily1")); scan.setBatch(1000);
10 ) org.apache.hadoop.hbase.client.ResultScanner
1 2 3 4 5 6 7 Scan scan = new Scan(); ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println("-----------------"); System.out.println("rowKey: " + new String(result.getRow())); System.out.println("address:city " + new String(result.getValue("address".getBytes(),"city".getBytes()))); }
2. API使用实例 启动Hadoop和HBase,在Eclipse中新建一个工程【hbase_java_api】,在工程中新建package【sds.hbase】,创建类【HbaseJavaApi】并将下面的代码复制其中并保存。另外,将HBase目录/apps/hbase/lib中所有jar包导入到工程当中即可运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 package sds.hbase; import java.io.IOException; import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.HColumnDescriptor;import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.*;import org.apache.hadoop.hbase.util.Bytes; public class HbaseJavaApi { public static Configuration conf; public static Connection conn; public static HBaseAdmin admin; public static void init () throws IOException { conf = HBaseConfiguration.create(); conf.set("hbase.rootdir" , "hdfs://localhost:9000/hbase" ); try { conn = ConnectionFactory.createConnection(conf); admin = (HBaseAdmin) conn.getAdmin(); }catch (IOException e){ e.printStackTrace(); } } public static void createTable (String tableName, String[] columnFamilys) throws IOException { try { if (admin.tableExists(tableName)) { System.out.println("table exists!" ); } else { HTableDescriptor tableDesc = new HTableDescriptor (TableName.valueOf(tableName)); for (String cf : columnFamilys) { HColumnDescriptor columnDescriptor = new HColumnDescriptor (cf); columnDescriptor.setMaxVersions(1 ); tableDesc.addFamily(columnDescriptor); } admin.createTable(tableDesc); System.out.println("create table success!" ); } }catch (Exception e){ e.printStackTrace(); } } public static void descTable (String tableName) throws Exception { try (Table table = conn.getTable(TableName.valueOf(tableName))){ HTableDescriptor desc = table.getTableDescriptor(); HColumnDescriptor[] columnFamilies = desc.getColumnFamilies(); System.out.println("columnfamilys:" ); for (HColumnDescriptor t:columnFamilies){ System.out.println(Bytes.toString(t.getName())); } }catch (Exception e){ e.printStackTrace(); } } public static boolean putRow (String tableName, String rowkey, String columnFamily, String qualifer, String data) throws IOException { try (Table table = conn.getTable(TableName.valueOf(tableName))){ Put p1 = new Put (Bytes.toBytes(rowkey)); p1.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(qualifer),Bytes.toBytes(data)); table.put(p1); System.out.println("put'" + rowkey + "'," + columnFamily + ":" + qualifer + "','" + data + "'" ); }catch (Exception e){ e.printStackTrace(); } return true ; } public static Result getRow (String tableName, String rowkey, String columnFamily, String qualifier) throws IOException { try (Table table = conn.getTable(TableName.valueOf(tableName))){ Get get = new Get (Bytes.toBytes(rowkey)); Result result = table.get(get); System.out.println("Get: " + new String (result.getValue(columnFamily.getBytes(),qualifier.getBytes()))); return result; }catch (Exception e){ e.printStackTrace(); } return null ; } public static ResultScanner scan (String tableName) throws IOException { try (Table table = conn.getTable(TableName.valueOf(tableName))){ Scan scan = new Scan (); ResultScanner scanner = table.getScanner(scan); return scanner; }catch (Exception e){ e.printStackTrace(); } return null ; } public static boolean deleteTable (String tableName) throws IOException { if (admin.tableExists(tableName)) { try { admin.disableTable(tableName); admin.deleteTable(tableName); } catch (IOException e) { e.printStackTrace(); System.out.println("Delete " + tableName + " 失败" ); } } return true ; } public static boolean deleteRow (String tableName, String rowkey) { try (Table table = conn.getTable(TableName.valueOf(tableName))){ Delete delete = new Delete (Bytes.toBytes(rowkey)); table.delete(delete); }catch (Exception e){ e.printStackTrace(); } return true ; } public static boolean deleteColumnFamily (String tableName, String columnFamily) { try { admin.deleteColumn(tableName,columnFamily); }catch (Exception e){ e.printStackTrace(); } return true ; } public static boolean deleteQualifier (String tableName,String rowkey, String columnFamily, String qualifer) { try (Table table = conn.getTable(TableName.valueOf(tableName))){ Delete delete = new Delete (Bytes.toBytes(rowkey)); delete.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(qualifer)); table.delete(delete); }catch (Exception e){ e.printStackTrace(); } return true ; } public static void close () { try { if (admin != null ) { admin.close(); } if (conn != null ) { conn.close(); } }catch (Exception e){ e.printStackTrace(); } } public static void main (String[] args) throws Exception { init(); String [] columnFamilys = {"address" ,"info" }; createTable("students" , columnFamilys); descTable("students" ); putRow("students" , "xiaoming" , "address" , "province" , "zhejiang" ); putRow("students" , "xiaoming" , "address" , "city" , "jinhua" ); putRow("students" , "xiaoming" , "info" , "age" , "20" ); putRow("students" , "xiaowang" , "address" , "city" , "hangzhou" ); getRow("students" , "xiaoming" , "info" , "age" ); ResultScanner scanner = scan("students" ); for (Result result : scanner) { System.out.println("-----------------" ); System.out.println("rowKey: " + new String (result.getRow())); System.out.println("address:city " + new String (result.getValue("address" .getBytes(),"city" .getBytes()))); } deleteTable("students" ); close(); } }
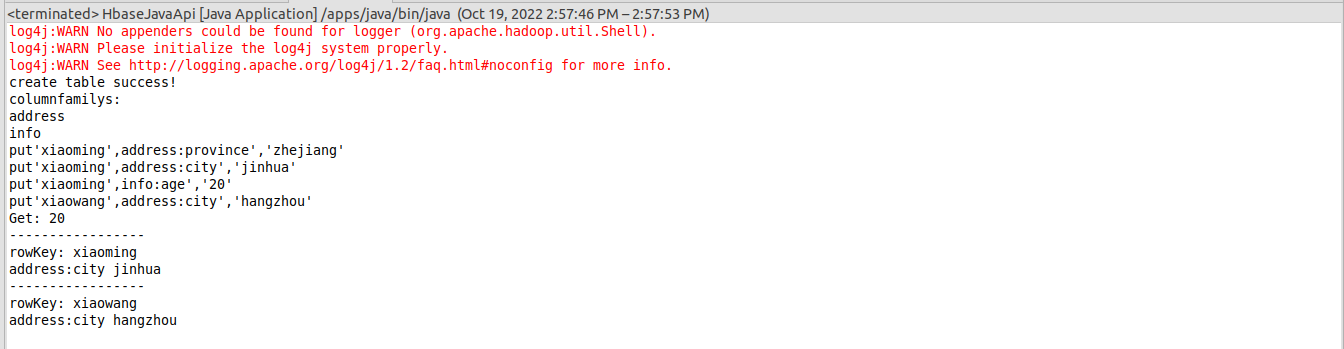
运行结果如下图所示,正确输出结果的同时,显示了log4j的警告信息。
注:运行前需离开安全模式
1 hadoop dfsadmin -safemode leave
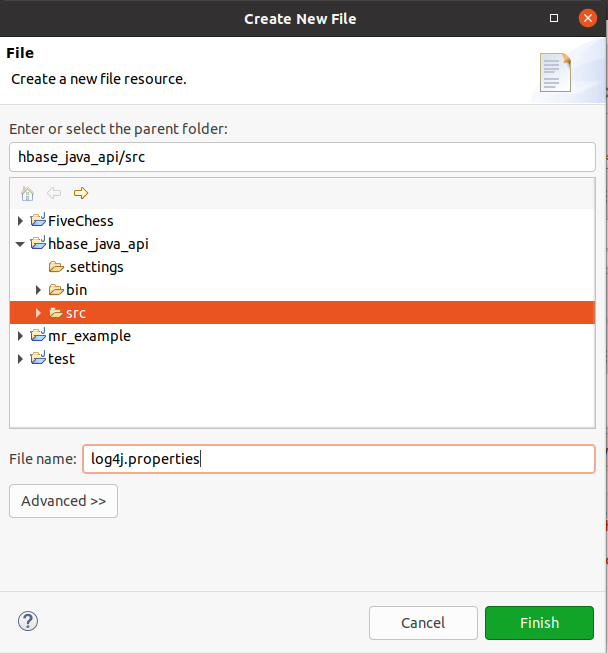
3. log4j设置 为了消除上面的警告信息,在工程src目录下新建文件log4j.properties,如下图所示
写入下面对log4j进行设置的内容
1 2 3 4 5 6 log4j.rootLogger=INFO, stdout # Console Appender log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern= %d{hh:mm:ss,SSS} [%t] %-5p %c %x - %m%n
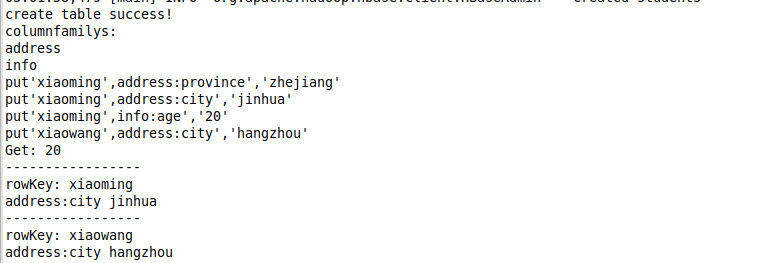
保存,再次运行,可以看到警告信息不再显示,按照我们在文件中设置的格式输出了日志信息。
二、将tsv文件数据存入HBase 在HDFS上创建目录/input/music/,用于存放数据文件
1 hadoop fs -mkdir /input/music/
将/data下的数据文件music.txt上传到hdfs,
1 hadoop fs -put /data/music.txt /input/music/
调用HBase提供的importtsv工具在HBase上创建表music, 并指定列族和列。命令格式
1 2 3 4 5 hadoop jar /apps/hbase/lib/hbase-server-1.4.0.jar importtsv \ -Dimporttsv.bulk.output=hdfs://localhost:9000/user/lei/tmp \ -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:singer,\ info:gender,info:ryghme,info:terminal \ music /input/music/
注意:-Dimporttsv.bulk.output的参数为将tsv文件转换为HFile文件以后存放的位置,不能提前存在,否则会报错。另外如果不加-Dimporttsv.bulk.output选项需要提前创建表格,数据可以直接写入HBase,相当于每行数据转换封装到PUT对象,然后插入到HBase表中。
在HBase中使用list命令查看表是否创建成功
此时数据还没有存入HBase,数据暂存在HDFS上的hdfs://localhost:9000/user/
lei/tmp目录下(具体目录根据自己的用户名相应的改变),
1 hadoop fs -ls -R /user/lei/tmp/
要把数据存入HBase,还需要调用HBase提供的completebulkload工具
1 2 hadoop jar /apps/hbase/lib/hbase-server-1.4.0.jar \ completebulkload hdfs://localhost:9000/user/lei/tmp music
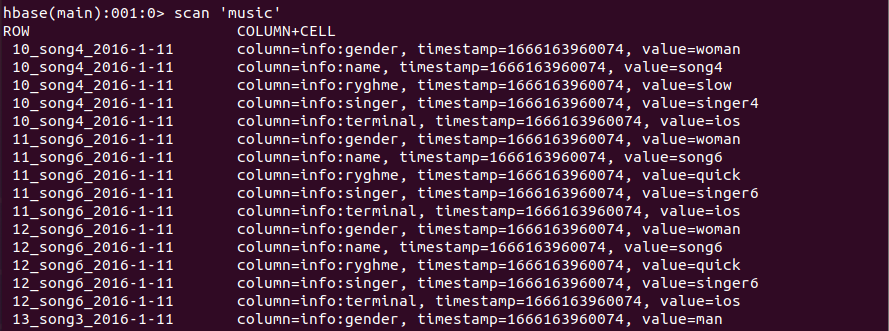
查看表中的数据
三、HBase 与MapReduce整合 MapReduce可以读取HBase中的数据作为输入,也可以将运行结果直接写入到HBase中。当HBase作为数据来源时,自定义Mapper需继承TableMapper,当HBase作为数据流向时,自定义Reducer需继承TableReducer。TableMapper类和TableReducer类是MapReduce专门为读取写入Hbase数据表而定制的。另外需调用TableMapReduceUtil类的静态方法initTableMapperJob来标识作为数据来源的HBase表名和自定义的Mapper类,用initTableReduerJob来标识作为数据输出流向的HBase表名和自定义的Reducer类。
下面的例子演示了从我们前一节创建的表格music读取数据,统计歌曲播放次数,将结果存入表namelist中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 package sds.hbase; import java.io.IOException; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.util.GenericOptionsParser; public class TableMapReduceDemo { static class MyMapper extends TableMapper<Text, IntWritable> { @Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { // 取出每行中的所有单元,实际上只扫描了一列(info:name) List<Cell> cells = value.listCells(); for (Cell cell : cells) { context.write( new Text(Bytes.toString(CellUtil.cloneValue(cell))), new IntWritable(1)); } } } static class MyReducer extends TableReducer<Text, IntWritable, Text> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int playCount = 0; for (IntWritable num : values) { playCount += num.get(); } // 为Put操作指定行键 Put put = new Put(Bytes.toBytes(key.toString())); // 为Put操作指定列和值,注意将数值型写入HBase一定要先转换为String类型,否则读取的时候不能正确转换 put.addColumn(Bytes.toBytes("details"),Bytes.toBytes("rank"),Bytes.toBytes(String.valueOf(playCount))); context.write(key, put); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.rootdir", "hdfs://localhost:9000/hbase"); conf.set("hbase.zookeeper.quorum", "localhost"); Job job = Job.getInstance(conf, "top-music"); // MapReduce程序作业基本配置 job.setJarByClass(TableMapReduceDemo.class); job.setNumReduceTasks(1); Scan scan = new Scan(); scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name")); // 使用hbase提供的工具类来设置job TableMapReduceUtil.initTableMapperJob("music", scan, MyMapper.class, Text.class, IntWritable.class, job); TableMapReduceUtil.initTableReducerJob("namelist", MyReducer.class, job); job.waitForCompletion(true); System.out.println("执行成功,统计结果存于namelist表中。"); } }
创建表namelist表用于存储结果
1 create 'namelist', 'details'
在Eclipse中创建工程并运行上面的代码,与从HDFS读取数据和存储数据的MapReduce任务进行对比。
执行成功以后,查看结果
练习:使用Java API写个小程序从HBase中获取上面的结果。 编写程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 package sds.hbase;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.HColumnDescriptor;import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.*;import org.apache.hadoop.hbase.util.Bytes;public class GetData { public static Configuration conf; public static Connection conn; public static HBaseAdmin admin; public static void init () throws IOException { conf = HBaseConfiguration.create(); conf.set("hbase.rootdir" , "hdfs://localhost:9000/hbase" ); try { conn = ConnectionFactory.createConnection(conf); admin = (HBaseAdmin) conn.getAdmin(); }catch (IOException e){ e.printStackTrace(); } } public static ResultScanner scan (String tableName) throws IOException { try (Table table = conn.getTable(TableName.valueOf(tableName))){ Scan scan = new Scan (); ResultScanner scanner = table.getScanner(scan); return scanner; }catch (Exception e){ e.printStackTrace(); } return null ; } public static void close () { try { if (admin != null ) { admin.close(); } if (conn != null ) { conn.close(); } }catch (Exception e){ e.printStackTrace(); } } public static void main (String[] args) throws Exception { init(); ResultScanner scanner = scan("namelist" ); for (Result result : scanner) { System.out.println("-----------------" ); System.out.println("rowKey: " + new String (result.getRow())); System.out.println("details:rank:" + new String (result.getValue("details" .getBytes(),"rank" .getBytes()))); } close(); } }
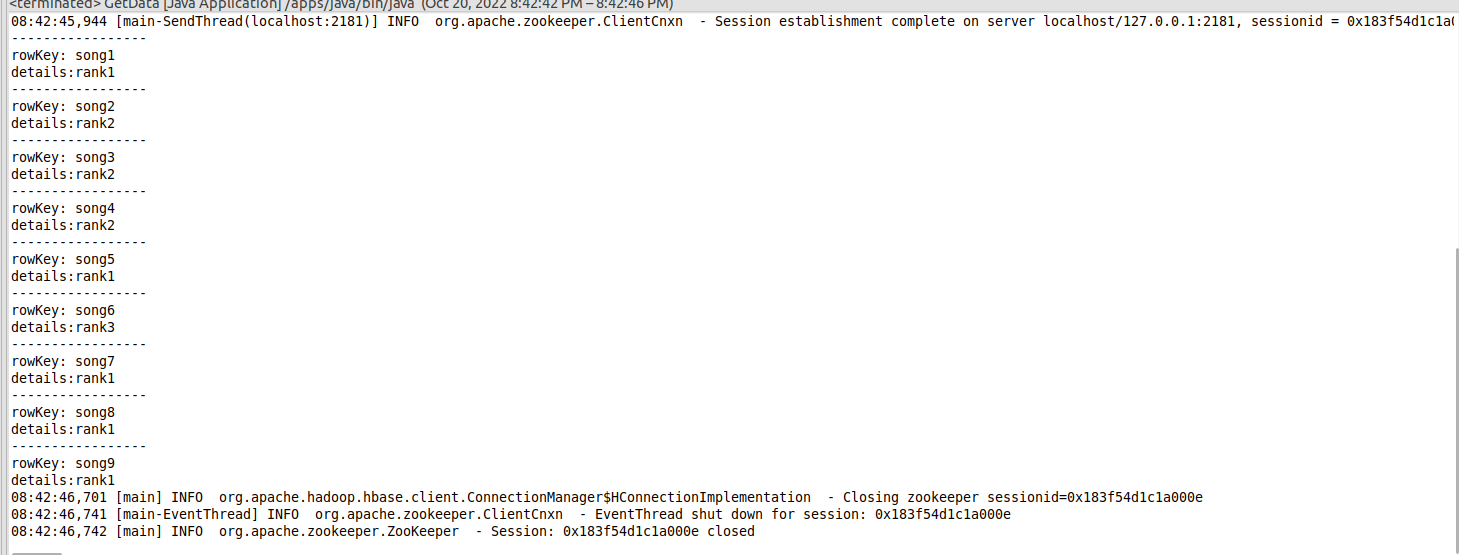
运行结果如下:
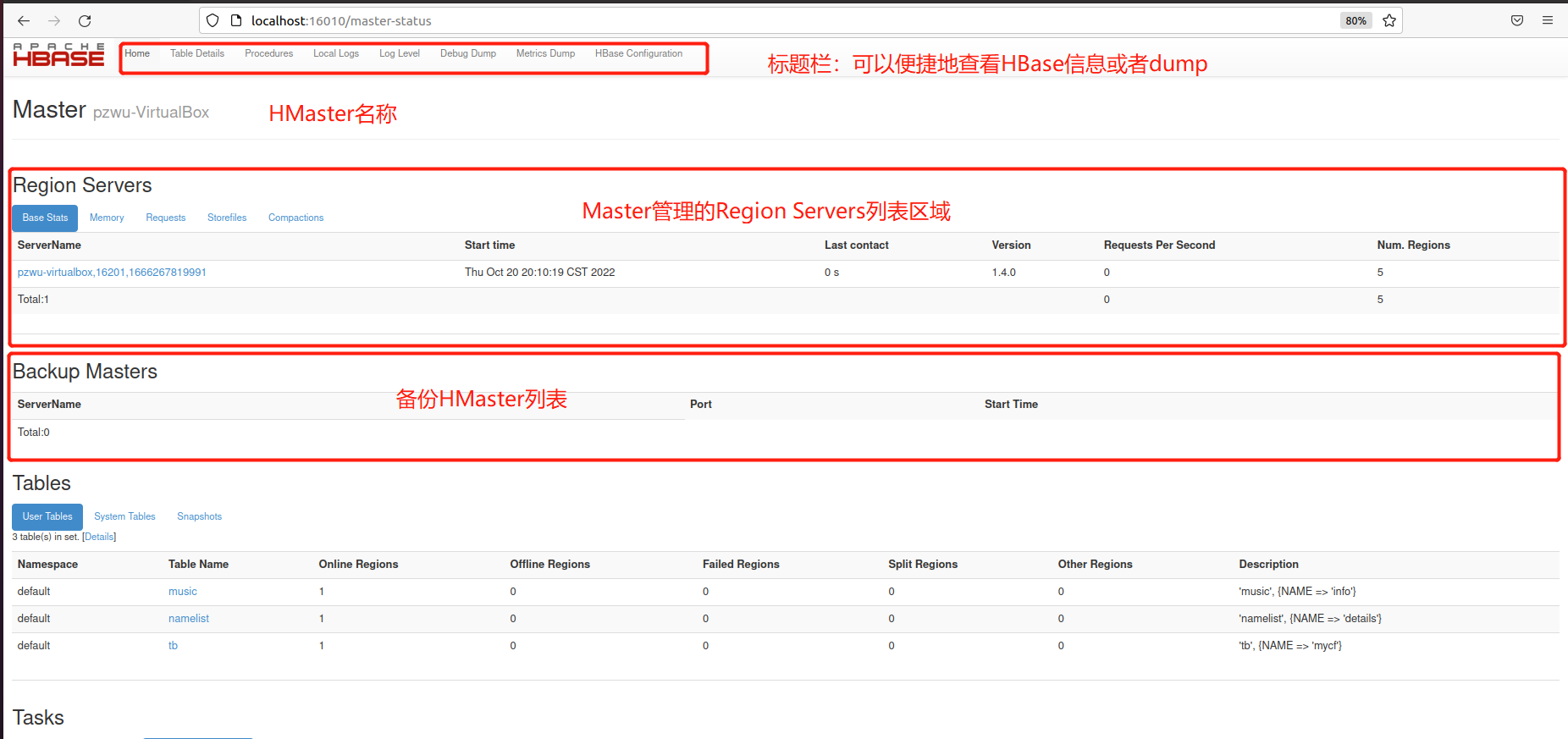
四、Web UI 使用浏览器打开 http://localhost:16010 HBase Web 管理页,查看以下信息。查看前面创建的表music和namelist的信息。
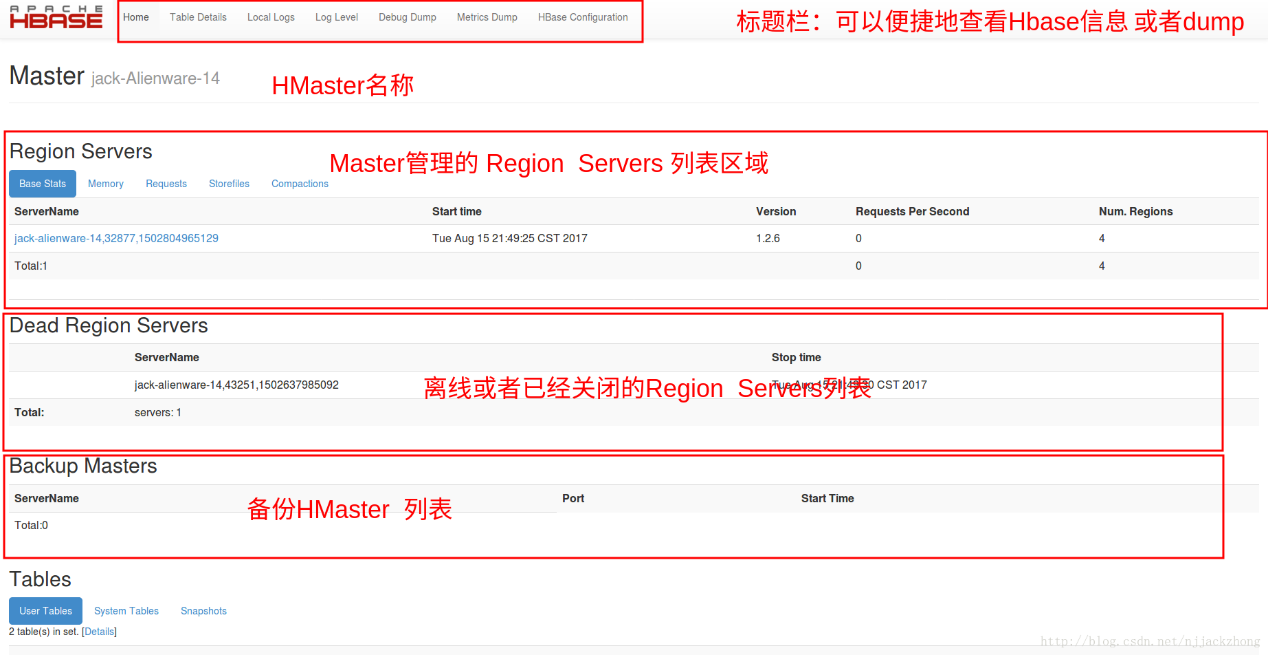
对比老师截图
缺少Dead Region Servers应该是无离线或者已经关闭的Region Servers