一、 HBase 基本概念;二、 HBase伪分布式安装;三、HBase Shell;四、注意
一、 HBase 基本概念
HBase是一个分布式的、面向列的、基于Google Bigtable的开源实现。名字来源于Hadoop database,即hadoop数据库。不同于一般的关系数据库,它可以存储非结构化数据,而且它是基于列的而不是基于行的模式。
- 利用Hadoop HDFS作为其文件存储系统,
- 利用Hadoop MapReduce来处理HBase中的海量数据,
- 利用Zookeeper作为协同服务。
表结构
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族/列簇(column family),每个列族/列簇下面可以有多个普通列。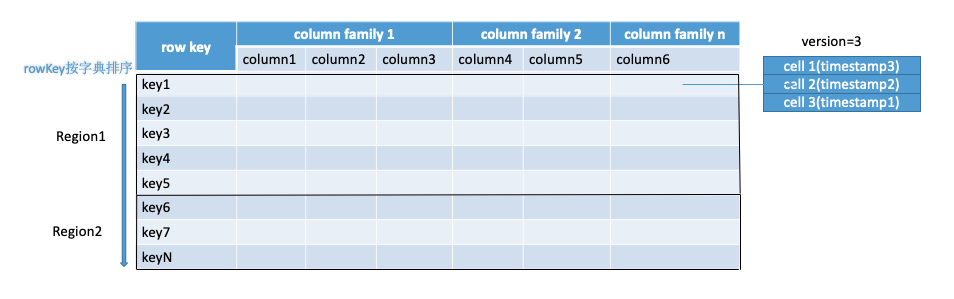
表(Table)
HBase采用表来组织数据,表由许多行和列组成,列划分为多个列族。
行(Row)
在表里面,每一行代表着一个数据对象。每一行都是由一个行键(Row Key)和一个或者多个列组成的。行键是行的唯一标识,行键并没有什么特定的数据类型,以二进制的字节来存储,按字母顺序排序。
行键 (Row Key)
行键,每一行的主键列,每行的行键要唯一,行键的值为任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在HBase内部,rowKey保存为字节数组byte[]。
列族(Column Family)
列族是每个子列的父级,每个子列都属于一个列族,一个列族包含一个或者多个相关列,创建表的时候需要指定列族,而不需要必须指定列。通过“列族名:列名”来表示某个具体的子列。HBase中的Schema就是由 TableName 和 Column Family Name构成。
列(Column)
列由列族(Column Family)和列限定符(Column Qualifier)联合标识,由“:”进行间隔,如 family:qualifier。
列限定符(Column Qualifier)
就是列族下的每个子列名称,或者称为相关列,或者称为限定符,只是翻译不同。通过columnFamily:column来定位某个子列。
存储单元 (Cell)
外观看到的每个单元格其实都可以对应着多个存储单元,默认情况下一个单元格对应着一个存储单元,一个存储单元可以存储一份数据,如果一个单元格有多个存储单元就表示一个单元格可以存储多个值。可以通过version来设置存储单元个数。可以通过
rowKey + columnFamily + column + timestamp来唯一确定一个存储单元。cell中的数据是没有类型的,全部是字节码形式存贮。
区域(Region)
Table在行的方向上分割为多个Region。Region是按大小分割的,每个表开始只有一个region,随着数据的增多,Region不断增大,当增大到一个阈值的时候,Region就会等分为两个新的Region,之后会有越来越多的Region。Region是HBase中分布式存储和负载均衡的最小单元。不同的Region分布到不同的RegionServer上。Region由一个或者多个Store组成, 每个Store保存一个columnFamily, 每个Store又由一个MemStore(存储在内存中)和0到多个StoreFile(存储在HDFS上)组成。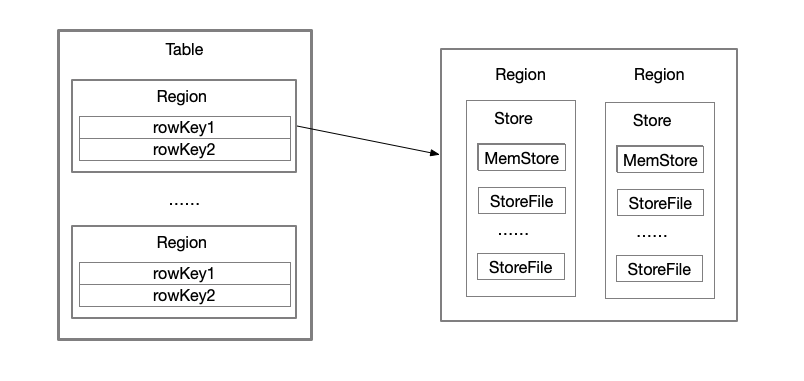
时间戳( Time Stamp)
每个cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的管理 (包括存贮和索引)负担,HBase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
命名空间(Namespace)
命名空间指对一组表的逻辑分组,类似关系数据库中的database,方便对表在业务上划分。
HBase系统默认定义了两个缺省的namespace:
- hbase:系统内建表,包含namespace和meta表;
- default:用户建表时未指定namespace的表都创建在此。
二、 HBase伪分布式安装
安装
将HBase的安装包hbase-1.4.0-bin.tar.gz 复制到/apps目录下并解压缩。
1 | cp ~/big_data_tools/hbase-1.4.0-bin.tar.gz /apps |
1 | tar zxvf hbase-1.4.0-bin.tar.gz |
重命名为hbase,删除压缩包hbase-1.4.10-bin.tar.gz。
1 | mv /apps/hbase-1.4.0 /apps/hbase |
1 | rm /apps/hbase-1.4.0-bin.tar.gz |
添加HBase的环境变量。打开用户环境变量配置文件~/.bashrc
1 | vim ~/.bashrc |
在文件末尾位置,追加HBase的bin目录路径相关配置,并保存退出。
1 | # Hbase |
到目前位置我们安装了Java,Hadoop和HBase,环境变量配置文件添加内容如下图所示
执行source命令,使环境变量生效。
1 | source ~/.bashrc |
此时就可以调用HBase的bin目录下的脚本了。先来查看一下HBase的版本信息。
1 | hbase version |

配置
切换到目录/apps/hbase/conf下,打开文件hbase-env.sh
1 | cd /apps/hbase/conf |
1 | vim hbase-env.sh |
在文件末尾追加下面的内容,并保存退出。
1 | export JAVA_HOME=/apps/java |
说明:
- JAVA_HOME为Java安装目录;
- HBASE_MANAGES_ZK表示是否使用HBase自带的Zookeeper环境;
- HBASE_CLASSPATH 配置HBase配置文件的位置。
打开文件hbase-site.xml。在两个之间添加如下内容,并保存退出。
1 | <property> |
配置项说明:
- hbase.master:HBase主节点地址。
- hbase.rootdir:HBase文件在HDFS上的存储位置。
- hbase.cluster.distributed:HBase是否为分布式模式。
- hbase.zookeeper.quorum:配置ZooKeeper服务器地址。
- hbase.zookeeper.property.dataDir:HBase在ZooKeeper上存储数据的位置。
注意:这里hbase.zookeeper.property.dataDir目录,需要提前创建。
1 | mkdir -p /data/tmp/zookeeper-hbase |
启动HBase。输入jps,查看Hadoop进程是否已经启动。若未启动,先启动Hadoop。
1 | /apps/hadoop/sbin/start-all.sh |
当Hadoop相关进程启动后,启动HBase服务。
1 | /apps/hbase/bin/start-hbase.sh |
输入jps,查看HBase相关进程。
输入jps,查看HBase相关进程。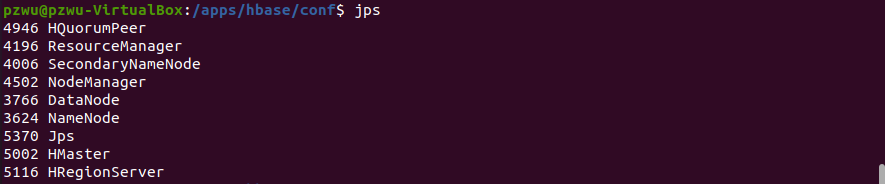
可以看到HBase的三个进程HMaster、HRegionServer、HQuorumPeer都已启动,其中HQuorumPeer为ZooKeeper进程。
测试
进入HBase Shell接口。
1 | hbase shell |
输入list的命令,查看当前有哪些HTable表。
1 | list |
创建一张表tb,表中含有一个列簇mycf。
1 | create 'tb','mycf' |
再次输入list,列出HBase中的表。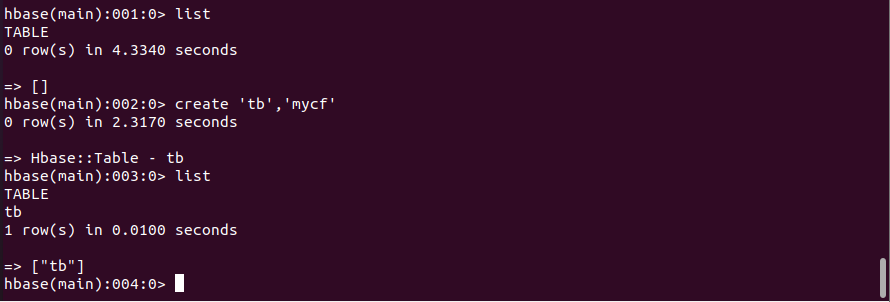
HBase在HDFS上的存储位置是在hbase-site.xml设置的,可以使用HDFS shell 命令进行查看。
三、HBase Shell
HBase Shell 是官方提供的一组命令,用于操作HBase。如果配置了HBase的环境变量,就可以在终端中输入hbase shell 命令进入命令行。
1 | hbase shell |

help命令
通过help命令可以查看hbase shell 支持的所有命令,HBase将命令分成了不同的组,如general, ddl, dml等。
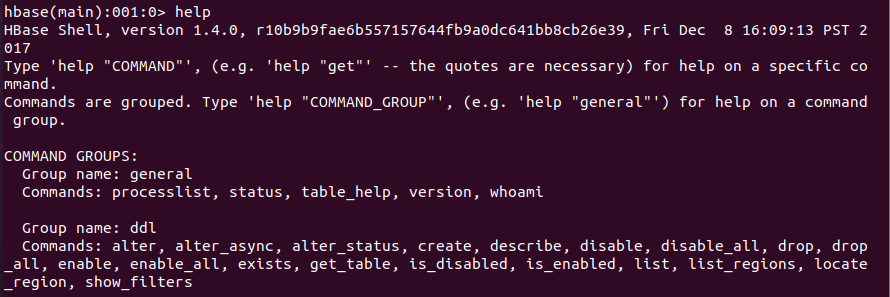
可以通过 help ‘命令名称’来查看命令的作用和用法。例如
1 | help 'list' |

General 命令
- 查询服务器状态

- 查询版本

DDL 操作
数据定义语言(Data Defination Language,DDL)操作主要用来定义、修改和查询表。
1.创建一个表
创建一个具有两个列族(address, info)的表students。
1 | create 'students','address','info' |

2.列出所有表

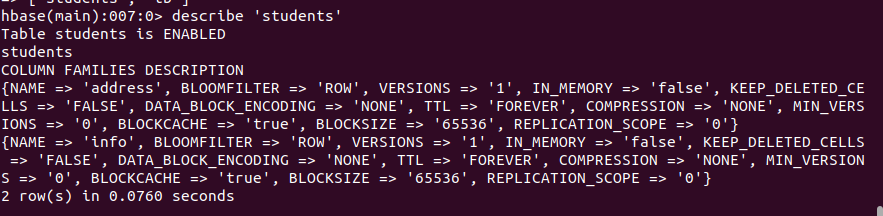
3.获取表的描述,自己弄清楚下图输出信息各项含义。
1 | describe 'students' |
4.删除一个列族
删除列族’info’
1 | alter 'students', {NAME => 'info', METHOD => 'delete'} |


5.删除一个表
要彻底删除一表数据和表结构,需要先disable,再drop。

6.查询表是否存在

7.查看表是否可用

DML 操作
DML(Data Manipulation Language,数据操作语言)操作主要用来对表的数据进行添加、修改、获取、删除和查询。
创建一个具有三个列族(name,address, info)的表students。
1 | create 'students','name','address','info' |
1.插入数据
给 students 表‘xiaoming‘行和’xiaowang’行插入数据
1 | put 'students', 'xiaoming', 'address:province', 'zhejiang' |

1 | put 'students', 'xiaoming', 'address:city', 'jinhua' |

1 | put 'students', 'xiaoming', 'info:age', '20' |

1 | put 'students', 'xiaowang', 'address:city', 'hangzhou' |

2.获取数据
获取 students 表的 xiaoming 行的所有数据。
1 | get 'students', 'xiaoming' |

获取 students 表的 xiaoming 行的address列族的所有数据。
1 | get 'students', 'xiaoming', 'address' |

获取 students 表的 xiaoming 行的address列族中city列的数据。
1 | get 'students', 'xiaoming', 'address:city' |

3.更新一条记录
更新students表的 xiaowang 行、address 列族中 province列的值。
1 | put 'students', 'xiaowang', 'address:city', 'shanghai' |

查看更新的结果。
1 | get 'students', 'xiaowang', 'address:city' |

4.全表扫描

5.删除一列
删除students 表 xiaoming行的address列族的列city。
1 | delete 'students', 'xiaoming', 'address:city' |
检查删除操作的结果。
1 | get 'students', 'xiaoming' |

6.删除行的所有单元格
使用“deleteall”命令删除students表 xiaoming 行的所有列。
1 | deleteall 'students', 'xiaoming' |

7.统计表中的行数
1 | count 'students' |

8.清空整张表
1 | truncate 'students' |
9.存储多个版本的数据
创建的表,默认列族的VERSIONS=1,也就是只会存取一个版本的列数据,当再次插入的时候,后面的值会覆盖前面的值。

修改表结构,让表支持存储3个本版
1 | alter 'students', {NAME=>'address', VERSIONS=>3} |
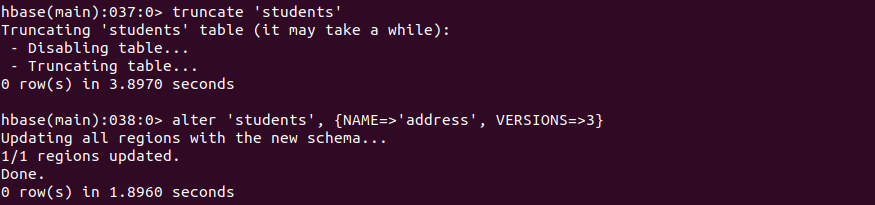
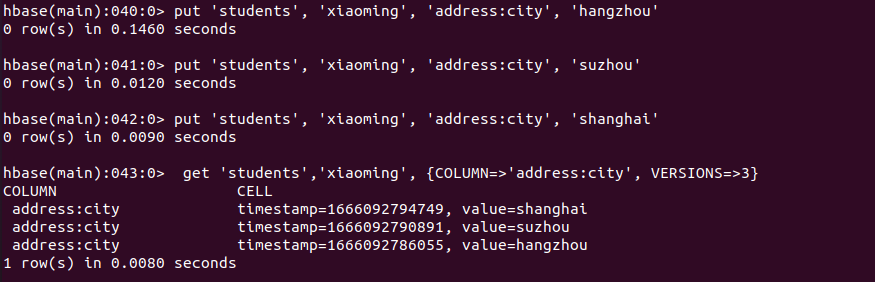
插入三行数据
1 | put 'students', 'xiaoming', 'address:city', 'hangzhou' |
1 | put 'students', 'xiaoming', 'address:city', 'suzhou' |
1 | put 'students', 'xiaoming', 'address:city', 'shanghai' |
一次读三个数据
1 | get 'students','xiaoming', {COLUMN=>'address:city', VERSIONS=>3} |
四、注意
报错如下
需离开安全模式,执行以下命令hadoop dfsadmin -safemode leave
1 | hadoop dfsadmin -safemode leave |