一、Hive 安装
1.复制apache-hive-2.3.5-bin.tar.gz到/apps目录下并解压。
1 | cp ~/big_data_tools/apache-hive-2.3.5-bin.tar.gz /apps |
1 | tar zxvf /apps/apache-hive-2.3.5-bin.tar.gz |
将/apps/apache-hive-2.3.5-bin,重命名为hive。
1 | mv /apps/apache-hive-2.3.5-bin/ /apps/hive |
删除压缩包
1 | rm /apps/apache-hive-2.3.5-bin.tar.gz |
2.设置环境变量。
1 | vim ~/.bashrc |
将Hive的bin目录,添加到用户环境变量PATH中
1 | # Hive |
下图是到目前位置已经设置的环境变量

执行source命令,使Hive环境变量生效。
1 | source ~/.bashrc |
3.拷贝MySQL驱动包。由于Hive需要将元数据存储到Mysql中,所以需要拷贝MySQL驱动包mysql-connector-java-5.1.46-bin.jar到hive的lib目录下。
1 | cp ~/big_data_tools/mysql-connector-java-5.1.46-bin.jar /apps/hive/lib/ |
4.设置配置文件
修改hive-site.xml文件
进入配置文件目录,将hive-default.xml.template重命为hive-site.xml
1 | cd /apps/hive/conf |
1 | mv hive-default.xml.template hive-site.xml |
创建tmp临时目录以存储临时文件
1 | mkdir -p /data/tmp/hive/tmp |
用vim打开hive-site.xml,在命令行模式执行(输入冒号:,在冒号后输入以下命令,回车)
1 | %s/${system:java.io.tmpdir}/\/data\/tmp\/hive\/tmp/g |
将${system:java.io.tmpdir}替换为上面创建的临时目录/data/tmp/hive/tmp,

一共有四处被替换。

再在命令行模型执行
1 | %s/${system:user.name}/root/g |

将${system:user.name}替换为root,共三处。
由于Hive的元数据会存储在Mysql数据库中,所以需要在Hive的配置文件中,指定Mysql的相关信息。
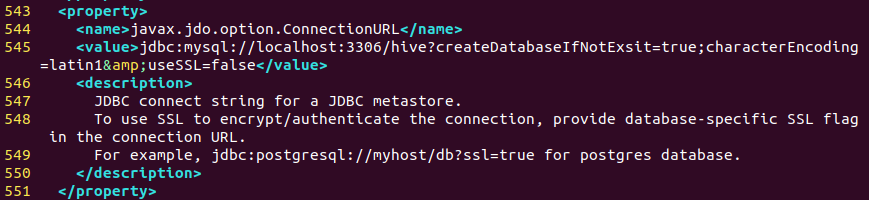
在545行,将javax.jdo.option.ConnectionURL的值设置为数据库链接字符串。
1 | <property> |
在1020行修改javax.jdo.option.ConnectionDriverName的值为连接数据库的驱动包。
1 | <property> |

在1045行修改javax.jdo.option.ConnectionUserName的值为Mysql数据库用户名为root。
1 | <property> |

在530行修改javax.jdo.option.ConnectionPassword的值为Mysql数据库的密码为123456。Mysql账号和密码安装Mysql的时候设置。
1 | <property> |

修改hive-env.sh文件
首先我们将hive-env.sh.template重命名为hive-env.sh。
1 | mv /apps/hive/conf/hive-env.sh.template /apps/hive/conf/hive-env.sh |
去掉48行的注释,修改为Hadoop的安装目录
1 | HADOOP_HOME=/apps/hadoop |
去掉51行的注释,修改为Hive的配置文件目录
export HIVE_CONF_DIR=/apps/hive/conf

修改hive-log4j2.properties文件
首先我们将hive-log4j2.properties.template重命名为hive-log4j2.properties。
1 | mv hive-log4j2.properties.template hive-log4j2.properties |
将24行修改为
1 | property.hive.log.dir = /data/tmp/hive/tmp/log |

5.安装配置Mysql,用于存储Hive的元数据。
使用apt命令安装MySQL。需要注意Ubuntu18.04使用apt默认安装的MySQL的版本为5.7.*,Ubuntu20.04默认安装的版本为8.0.*,两个版本的命令略有区别,后面用到会给出两个版本的配置方式。
1 | sudo apt install mysql-server |
安装以后服务会自动启动,也可执行以下命令,查看Mysql的运行状态。
1 | sudo service mysql status |
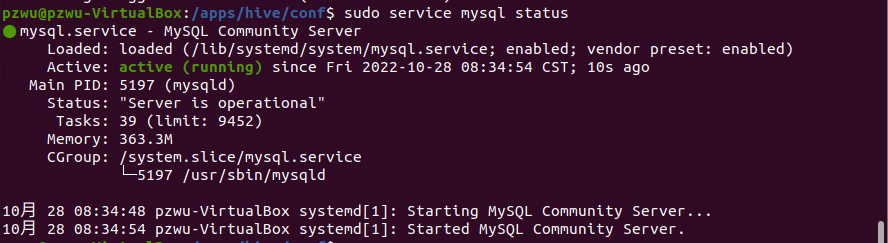
通过输出,可以看出Mysql已启动。如果没有启动可以执行以下命令进行启动
1 | sudo service mysql start |
接着为root用户添加密码。打开终端,切换到root用户
1 | sudo -i |
运行mysql进入Mysql交互模式
1 | mysql |
执行以下命令将root密码设置为123456。
1 | update mysql.user set authentication_string=PASSWORD('123456'),plugin='mysql_native_password' where user='root'; |
Ubuntu 20.04对应的MySQL为8.0以上版本,使用下面的命令设置root账号密码。
1 | ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456'; |
运行以下命令使修改生效,
1 | flush privileges; |
执行exit,退出MySQL。
经过上面的设置,以后进入MySQL就不需要切换到系统root用户了,使用如下命令进行登录
1 | mysql -u root -p |
此时会提示输入密码,输入上面设置的密码123456,回车。
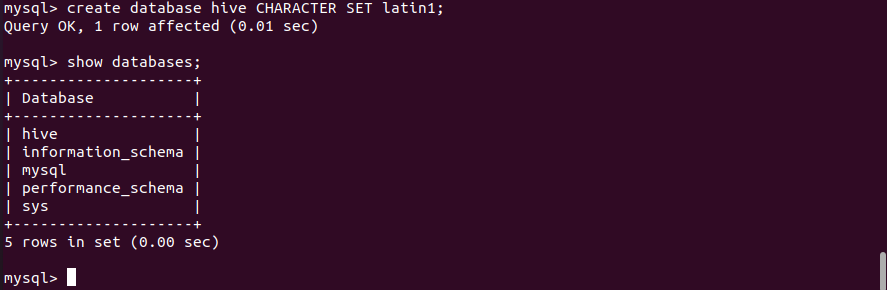
6.创建名为hive的数据库,编码格式为latin1,用于存储元数据。在Mysql交互模式下,执行以下命令创建名为hive的数据库
1 | create database hive CHARACTER SET latin1; |
查看数据库是否创建成功。
1 | show databases; |
7.远程登录设置
我们在后面的章节会从Hive往MySQL导数据,需要从其他节点访问MySQL,因此要授予登录用户远程连接的权限,这里以root账号为例,执行以下命令
1 | grant all privileges on *.* to root@'%' identified by '123456'; |
1 | flush privileges; |
Ubuntu 20.04 对应的MySQL为8.0以上版本。下面的命令首先创建一个可以从任意节点访问MySQL的用户root,然后赋予其权限。
1 | CREATE USER 'root'@'%' IDENTIFIED BY '123456'; |
1 | grant all privileges on *.* to root@'%'; |
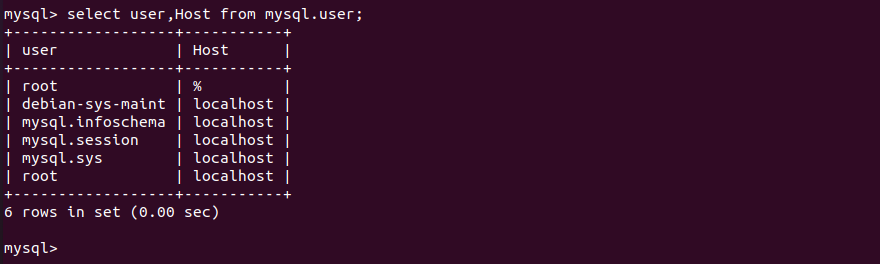
执行以后就会在库Mysql的 表user中添加相应的信息。输入以下命令进行查看
1 | select user,Host from mysql.user; |
另外,需要在MySQL配置文件/etc/mysql/mysql.conf.d/mysqld.cnf中注释掉31行

设置以后重启MySQL服务
1 | sudo service mysql restart |
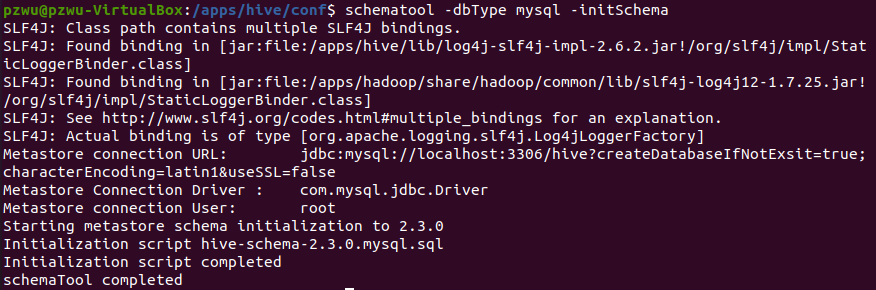
8.初始化元数据库。执行以下命令初始化元数据库
1 | schematool -dbType mysql -initSchema |
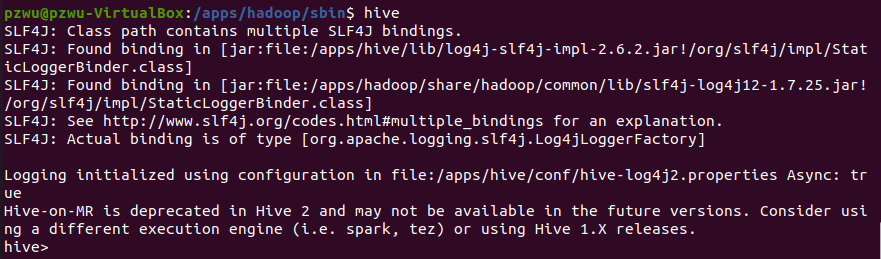
9.启动Hive。初始化以后,就可以启动Hive了。由于Hive对数据的处理,依赖MapReduce计算模型,所以启动Hive前需要保证Hadoop相关进程已经启动。在终端中,直接输入hive便可启动Hive命令行模式。
1 | hive |
输入Hive QL语句查询数据库,测试Hive是否可以正常使用。比如,下面的命令显示所有数据库,可以看到Hive有一个默认的名为default的库。
1 | show databases; |

Hive 安装完成。
二、Hive QL
Hive QL 是Hive支持的类SQL的查询语言。Hive QL大体可以分为DDL,DML,UDF三种类型。
DDL(Data Definition Language) 可以创建数据库,数据表,进行数据库和表的删除;
DML(Data Manipulation Language) 可以进行数据的添加、查询;
UDF(User Defined Function) 支持用户自定义查询函数。
2.1 Hive 中的数据模型
Database:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹

Table:在 HDFS 中表现为所属 database 目录下一个文件夹
External table:与 Table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
Partition:在 HDFS 中表现为 table 目录下的子目录
Bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件
View:与传统数据库类似,只读,基于基本表创建
2.2 DDL数据库定义语言
2.2.1 内部表
与数据库中的 Table 在概念上是类似,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路径为:warehouse/test。 warehouse是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录
1 | create table iris(Index int, SepalLength float, SepalWidth float, PetalLength float, PetalWidth float, Species string) row format delimited fields terminated by ',' stored as textfile; |

加载数据
Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。如果表中存在分区,则必须指定分区名。
从本地加载数据
加载本地数据,指定LOCAL关键字,即本地,可以同时给定分区信息 。
1 | load data local inpath '/home/pzwu/Iris.csv' into table iris; |

从HDFS中加载
Hive 会使用在 Hadoop 配置文件中定义的 fs.defaultFS 指定的Namenode 的 URI来自动拼接完整路径。
清空表格,重新从HDFS加载数据

提前在HDFS上创建文件夹/input/iris/,并上传数据文件iris.csv。
1 | load data inpath '/input/iris/Iris.csv' into table iris; |
OVERWRITE
指定 OVERWRITE , 目标表(或者分区)中的内容(如果有)会被删除,然后再将路径指向的文件/目录中的内容添加到表/分区中。
1 | load data inpath '/input/iris/iris.csv' overwrite into table iris; |
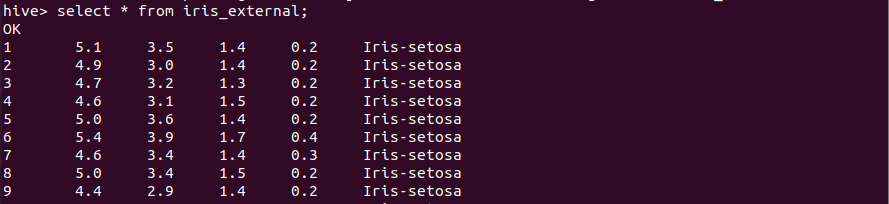
2.2.2 外部表
外部表和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。外部表主要指向已经在 HDFS 中存在的数据,可以创建 Partition。注意:location后面跟的是目录,不是文件,Hive将依据默认配置的HDFS路径,自动将整个目录下的文件都加载到表中。Hive 默认数据仓库路径下,不会生成外部表的文件目录。
1 | create external table iris_external(Index int,SepalLength float, SepalWidth float, PetalLength float, PetalWidth float, Species string) row format delimited fields terminated by ',' location '/input/iris/'; |
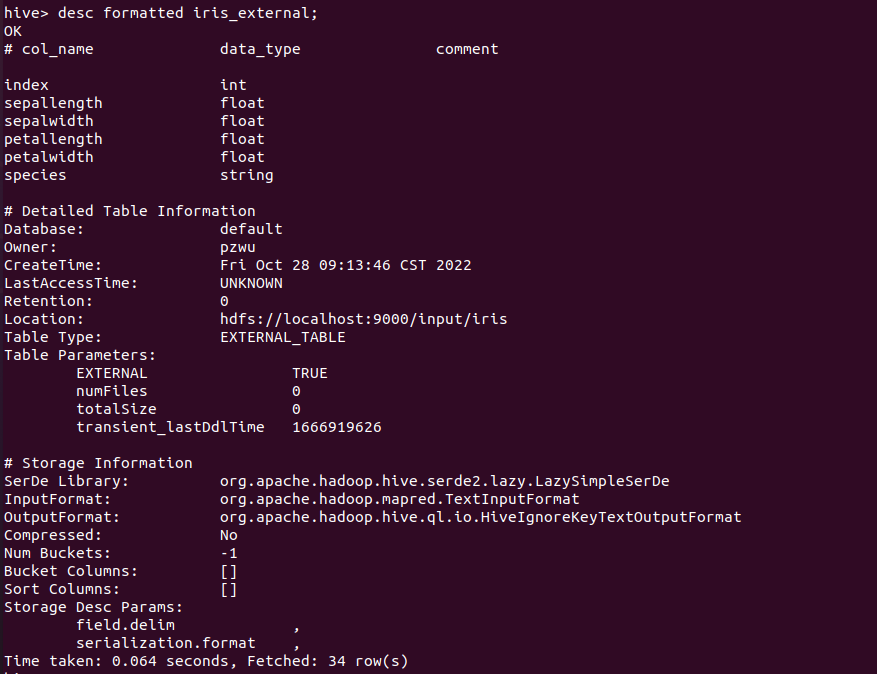
查看表信息
使用如下命令可以查看表的详细信息,包括location的指向。
1 | desc formatted iris_external; |
查看数据
外部表与内部表的差异
- 内部表的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除;
- 外部表只有一个过程,加载数据和创建表同时完成,并不会移动数据到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接。
注:Hive不能清空外部表(外部表不被hive管理,hive只维护到外部表的引用关系)。因此执行truncate操作,只能对内部表进行。
2.2.3 分区表
所谓分区(Partition) 对应于数据库的 Partition 列的密集索引。分区字段要写在partitoned by()中。
1 | create table iris_partition(Index int,SepalLength float, SepalWidth float, PetalLength float, PetalWidth float) partitioned by(Species string) row format delimited fields terminated by ',' stored as textfile; |

加载数据
将三个类别的鸢尾花数据分别存到三个csv文件中
1 | head -50 /home/pzwu/Iris.csv > setosa.csv |
1 | sed -n '51,100p' /home/pzwu/Iris.csv > versicolor.csv |
1 | sed -n '101,150p' /home/pzwu/Iris.csv > virginica.csv |

然后把三个文件的数据加载到分区表的三个分区中,
1 | load data local inpath '/home/pzwu/setosa.csv' into table iris_partition partition(Species='setosa'); |

1 | load data local inpath '/home/pzwu/versicolor.csv' into table iris_partition partition(Species='versicolor'); |

1 | load data local inpath '/home/pzwu/virginica.csv' into table iris_partition partition(Species='virginica'); |

增加分区
1 | alter table iris_partition add partition (Species='unknown'); |

查看分区
1 | show partitions iris_partition; |

删除分区
1 | alter table iris_partition drop if exists partition (Species='unknown'); |

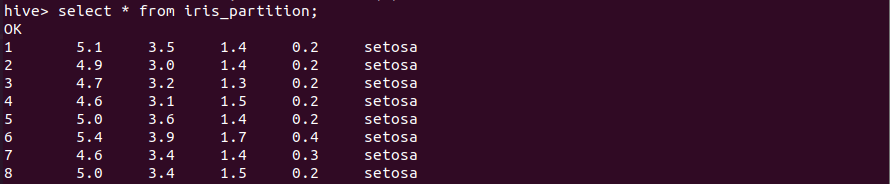
查询分区表数据
1 | select * from iris_partition; |
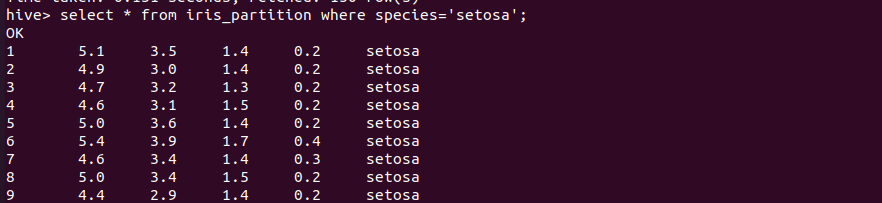
按分区查询
1 | select * from iris_partition where species='setosa'; |
按sepallength排序查询前5条记录
1 | select * from iris_partition sort by sepallength desc limit 5; |

查询表结构
1 | desc iris_partition; |
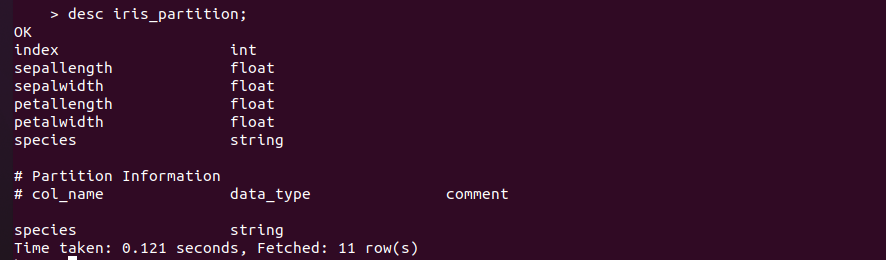
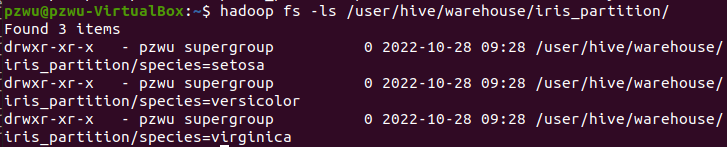
在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。
2.2.4 桶表
桶是比表或分区更为细粒度的数据范围划分。针对某一列进行桶的组织,对列值哈希,然后除以桶的个数求余,决定将该条记录存放到哪个桶中。跟MapReduce中的HashPartitioner的原理一样。在MR中,按照key的Hash值去模除以reductTask的个数。在Hive中时按照分桶字段的Hash值去模除以分桶的个数。 分桶的主要作用:数据抽样、提高查询效率。
创建桶表
1 | create table iris_bucket(Index int, SepalLength float, SepalWidth float, PetalLength float, PetalWidth float, Species string) clustered by(Species) into 3 buckets row format delimited fields terminated by ','; |

说明:
- clustered by :指定需要进行分桶的列
- into x buckets: 指定进行分桶的数量
加载数据
导入数据不能使用load data这种方式,需要从别的表来引用,使用load data 加载数据,则不能生成桶数据。另外,需要先set hive.enforce.bucketing = true,才可以将数据正常写入桶中。
1 | insert overwrite table iris_bucket select * from iris; |
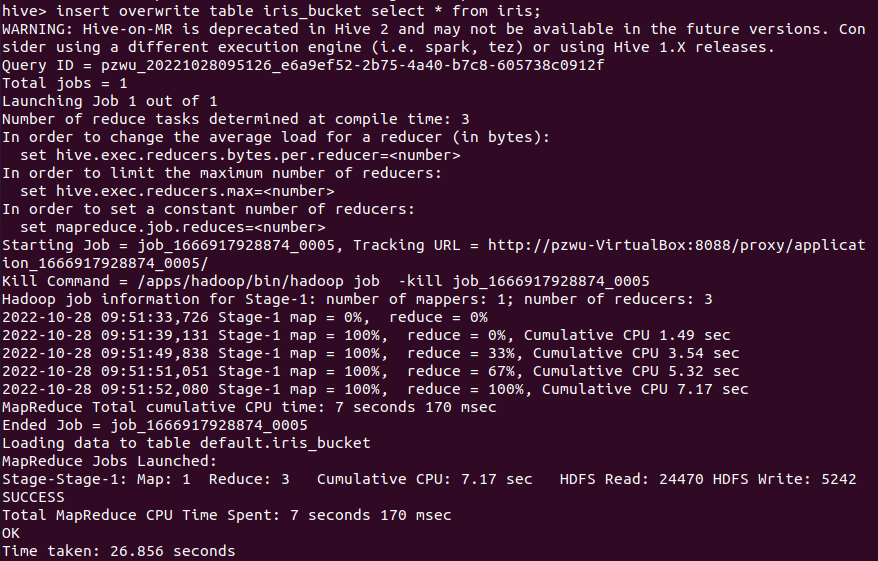
HDFS上的目录结构
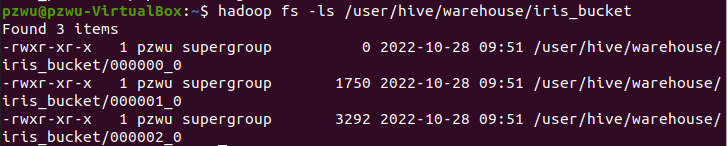
查询全部数据
1 | select * from iris_bucket; |
抽样查询
1 | select * from iris_bucket tablesample(bucket 1 out of 3 on Species); |
用法:TABLESAMPLE(BUCKET x OUT OF y) 。y必须是Table总Bucket数的倍数或者因子。Hive根据y的大小,决定抽样的比例。例如,Table总共分了64份,当y=32时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个Bucket开始抽取。例如,Table总Bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个Bucket和第(3+16=)19个Bucket的数据。
分区中的数据可以被进一步拆分成桶
1 | create table iris_partition_bucket(Index int, SepalLength float, SepalWidth float, PetalLength float, PetalWidth float) partitioned by(Species string) clustered by(SepalLength) into 3 buckets row format delimited fields terminated by ','; |

插入数据
将不同类型的鸢尾花保存到不同的分区并将数据分桶。
1 | insert overwrite table iris_partition_bucket partition(Species='setosa') select Index, SepalLength, SepalWidth, PetalLength, PetalWidth from iris where species='Iris-setosa'; |
1 | insert overwrite table iris_partition_bucket partition(Species='versicolor') select Index, SepalLength, SepalWidth, PetalLength, PetalWidth from iris where species='Iris-versicolor'; |
1 | insert overwrite table iris_partition_bucket partition(Species='virginica') select Index, SepalLength, SepalWidth, PetalLength, PetalWidth from iris where species='Iris-virginica'; |
指定overwrite关键字,目标文件夹中之前存在的数据将会被先删除掉,如果没有这个关键字,仅仅会把新增的文件增加到目标文件夹中,而不会删除之前的数据。
目录结构
在HDFS上每个分区是一个目录
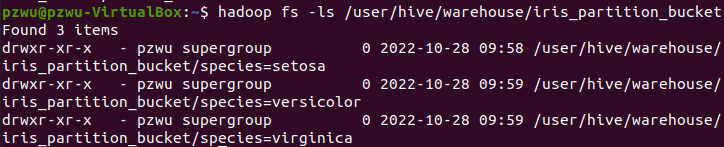
每个分区目录下有分桶数个文件
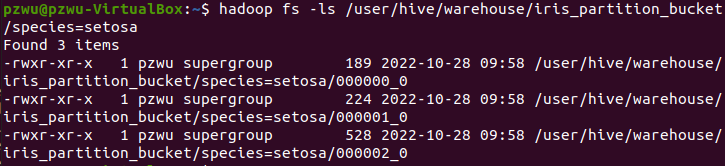
桶的概念其实就是MapReduce的分区的概念,两者完全相同。物理上每个桶就是目录里的一个文件,一个作业产生的桶(输出文件)数量和reduce任务个数相同。
而分区表的概念,则是新的概念。分区代表了数据的仓库,也就是文件夹目录。每个文件夹下面可以放不同的数据文件。通过文件夹可以查询里面存放的文件。但文件夹本身和数据的内容毫无关系。桶则是按照数据内容的某个值进行分桶,把一个大文件散列称为一个个小文件。 这些小文件可以单独排序。如果另外一个表也按照同样的规则分成了一个个小文件。两个表join的时候,就不必要扫描整个表,只需要匹配相同分桶的数据即可。效率当然大大提升。同样,对数据抽样的时候,也不需要扫描整个文件。只需要对每个分区按照相同规则抽取一部分数据即可。
删除表
1 | DROP TABLE [IF EXISTS] table_name; |
DROP TABLE 语句用于删除表的数据和元数据(表结构)。对应外部表,只删除Metastore中的元数据,而外部数据保存不动。
如果只想删除表数据,保留表结构,跟MySQL类似,使用TRUNCATE语句。truncate 不能删除外部表!因为外部表里的数据并不是存放在Hive Meta store中。
1 | truncate table table_name; |
2.2.5 数据库操作
创建数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_name]
[LOCATION hdfs_path]
[WITH DBPROPERTIES(property_name=property_value,…)];
例如创建名为hive_db_test的数据库,并设置创建者和创建时间。
1 | create database if not exists hive_db_test with dbproperties ('creator' ='pzwu', 'date' = '2020-08-31'); |

切换数据库
1 | use hive_db_test; |
查看数据库
1 | describe database hive_db_test; |

可以看到数据库在HDFS上的存储位置hdfs://localhost:9000/user/hive/warehouse/,每个数据库一个文件。
查看当前使用的数据库
1 | select current_database(); |

删除数据库
1 | drop database hive_db_test; |

默认情况下,Hive不允许用户删除一个包含表的数据库。用户要么先删除数据库中的表,再删除数据库;要么在删除命令的最后加上关键字CASCADE,这样Hive会先删除数据库中的表,再删除数据库,
命令如下(务必谨慎使用此命令)
1 | drop database my_hive_test CASCADE; |
查看所有数据库
1 | show databases; |

2.3 DML数据操作语言
2.3.1表操作
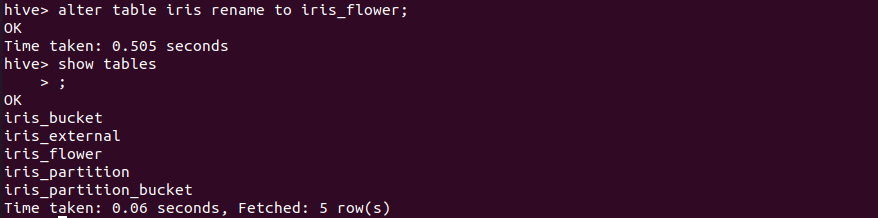
重命名表
1 | alter table iris rename to iris_flower; |
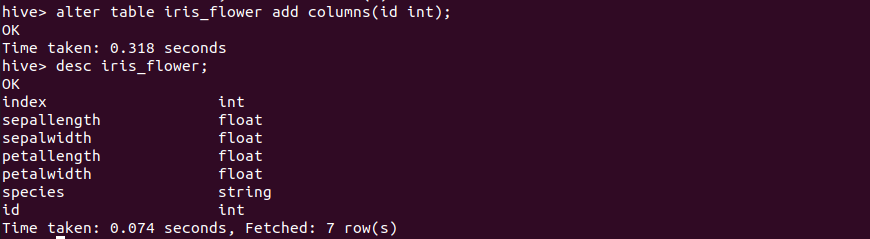
增加列
1 | alter table iris_flower add columns(id int); |
修改列名
将列id改为num
1 | alter table iris_flower change id num int; |
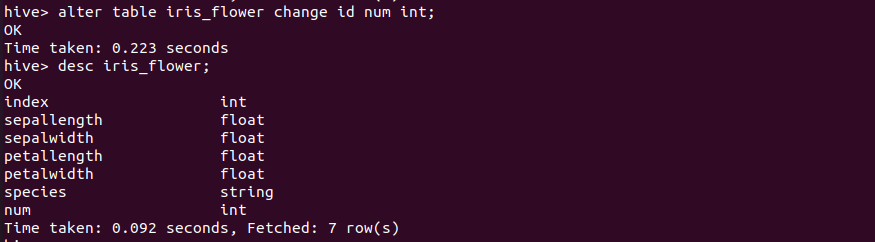
创建表接收查询结果
查询iris_flower表中Sepal_Length<5的数据存入新表iris_result
1 | create table iris_result as select SepalLength, SepalWidth, PetalLength, PetalWidth from iris_flower where SepalLength<5; |
查看结果
1 | select * from iris_result; |
导出数据
- 导出到本地。将iris_result中的数据导出到文件夹/home/lei/result(非常重要:新建一个文件夹,因为指定的目录会被清空)执行语句后,会在本地目录的/home/lei/result下 生成一个名为000000_0的数据文件。导出的数据列之间的分隔符默认是^A(ascii码是\001)。
1 | insert overwrite local directory '/home/lei/result' select * from iris_result; |

- 导出到HDFS。将iris_result中的数据导出到HDFS文件/output/iris/。导出路径为文件夹路径,不必指定文件名。执行语句后,会在HDFS目录的/output/iris下生成一个名为000000_0的数据文件。
1 | insert overwrite directory '/output/iris/' select * from iris_result; |
查询全表
1 | select * from iris_flower; |
查询部分字段
1 | select SepalLength, PetalLength, Species from iris_flower; |
统计每个类型的鸢尾花数量
1 | select collect_set(species)[0], count(*) from iris_flower group by species; |

注意:
- Hive不允许直接访问非group by字段;
- 对于非group by字段,可以用Hive的collect_set函数收集这些字段,返回一个数组;
- 使用数字下标,可以直接访问数组中的元素。
统计函数
1 | select max(SepalLength), min(SepalWidth), avg(PetalLength), sum(PetalWidth) from iris_flower; |

2.4 Hive实现WordCount
1.新建Hive表
1 | create table docs(line string) row format delimited fields terminated by ',' stored as textfile; |

2.从HDFS加载数据到hive表中
1 | load data inpath '/input/wordcount/testfile' into table docs; |

3.数据文件之前已经上传到HDFS,内容如下

4.在Hive中查看表的内容

5.分割文本
1 | SELECT split(line, ' ') AS word FROM docs; |

注:通过观察上面cat的内容,可知每个句子之间行间空了一行
6.行转列
1 | SELECT explode(split(line, ' ')) AS word FROM docs; |
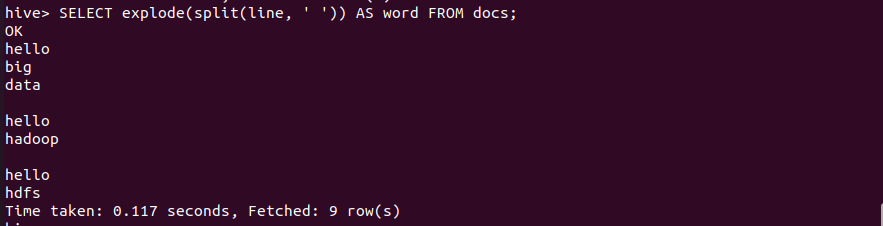
7.统计词频
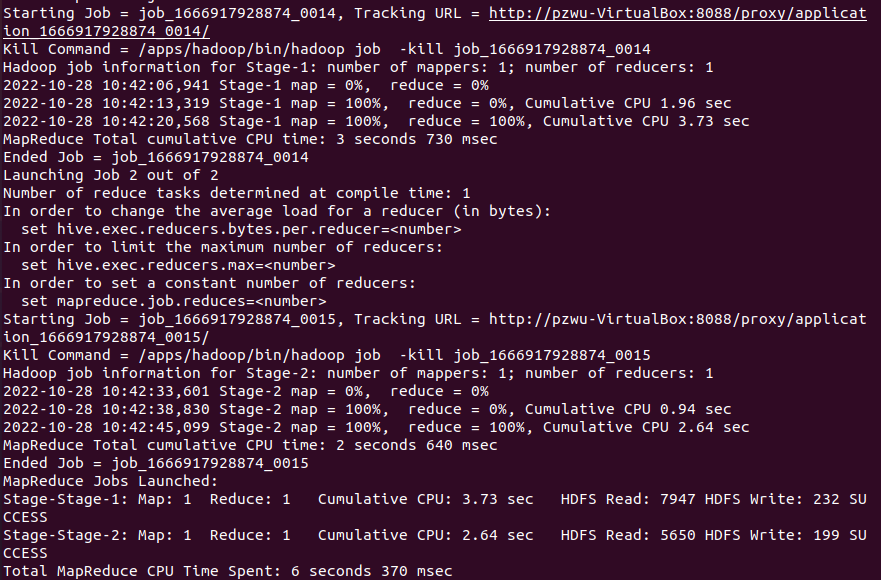
把上面的命令组合到一起
1 | SELECT word, count(*) AS count FROM |

从日志信息可以看出,Hive将sql命令转换成了MapReduce任务。
2.5 常用命令
- 查询数据库:show databases;
- 模糊搜索表:show tables like ‘name‘;
- 删除数据库:drop database dbname;
- 删除数据表:drop table tablename;
- 查看表结构信息:desc table_name;
- 查看详细表结构信息: desc formatted table_name;
- 查看分区信息: show partitions table_name;